[论文解读] SpeechTokenizer: Unified Speech Tokenizer for Speech Large Language Models
论文提出 SpeechTokenizer,一种基于统一的 RVQ 的语音标记器,通过语义蒸馏将语义令牌与声学令牌合并,构建 Unified Speech Language Model (USLM),并在重建、SLMTokBench 性能以及比基线有零-shot TTS 改进方面表现出色。
Current speech large language models build upon discrete speech representations, which can be categorized into semantic tokens and acoustic tokens. However, existing speech tokens are not specifically designed for speech language modeling. To assess the suitability of speech tokens for building speech language models, we established the first benchmark, SLMTokBench. Our results indicate that neither semantic nor acoustic tokens are ideal for this purpose. Therefore, we propose SpeechTokenizer, a unified speech tokenizer for speech large language models. SpeechTokenizer adopts the Encoder-Decoder architecture with residual vector quantization (RVQ). Unifying semantic and acoustic tokens, SpeechTokenizer disentangles different aspects of speech information hierarchically across different RVQ layers. Furthermore, We construct a Unified Speech Language Model (USLM) leveraging SpeechTokenizer. Experiments show that SpeechTokenizer performs comparably to EnCodec in speech reconstruction and demonstrates strong performance on the SLMTokBench benchmark. Also, USLM outperforms VALL-E in zero-shot Text-to-Speech tasks. Code and models are available at https://github.com/ZhangXInFD/SpeechTokenizer/.
研究动机与目标
- 动机:需要离散的语音表示与文本对齐,同时保留完整的语音信息。
- 评估现有的语义和声学令牌类型,并识别它们在语音语言建模中的局限性。
- 提出一个统一的标记器(SpeechTokenizer),在 RVQ 层之间解耦内容与旁语信息。
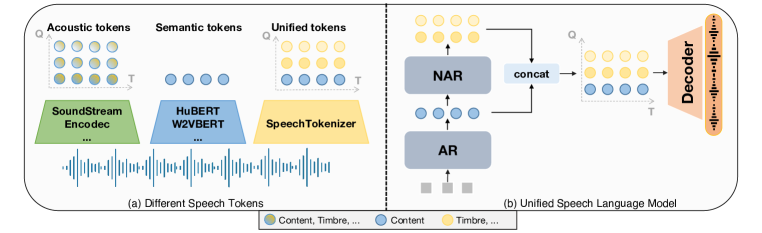
- 开发一个统一的语音语言模型(USLM),利用 SpeechTokenizer 进行自回归与非自回归生成。
- 展示具有竞争力的语音重建、强劲的 SLMTokBench 性能,以及相较基线的改进的零-shot TTS。
提出的方法
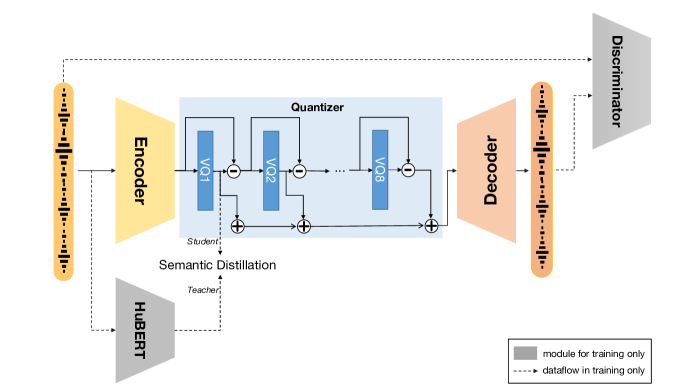
- 采用类似 EnCodec 的编码器-解码器 RVQ-GAN 框架,并进行时间分辨率下采样。
- 引入语义蒸馏,其中第一层 RVQ 由语义教师(HuBERT)通过连续和伪标签蒸馏引导。
- 以重建 GAN 目标加 RVQ 承诺损失与语义蒸馏损失进行训练。
- 在 RVQ 层之间分层解耦信息,使第一层捕获内容,而后续层编码旁语细节。
- 构建一个统一的语音语言模型(第一层标记上自回归;后续层进行非自回归),并进行零-shot TTS 训练。
- 通过 SLMTokBench 评估文本对齐与信息保留,并评估零-shot TTS 与一拍语音转换。
实验结果
研究问题
- RQ1与单独的语义令牌或声学令牌相比,统一的 SpeechTokenizer 是否能够同时提升文本对齐和语音信息保留?
- RQ2在语义引导下的分层 RVQ 令牌化是否实现了有效的内容建模和高质量的语音重构?
- RQ3所得的 USLM 在零-shot 文本到语音方面是否优于现有系统,并保持或提升内容准确性?
- RQ4语义教师的选择(如 HuBERT L9 与平均值或单位)如何影响下游文本对齐和重构?
- RQ5在像一拍语音转换这样的任务中,RVQ 层之间信息解耦的作用是什么?
主要发现
- SpeechTokenizer 在语音重建方面与 EnCodec 相当,并且可以得到更低的 WER,表明内容保留较强。
- 在 SLMTokBench 上,SpeechTokenizer 令牌显示出改进的文本互信息,并且相比基线具有竞争力或更好的内容保留;后期 RVQ 层增强了音色保留。
- 在零-shot TTS 中,使用 SpeechTokenizer 的统一语音语言模型在 WER 更低、说话人相似度更高方面优于 VALL-E。
- USLM 展示出在零-shot TTS 中更高的说话人相似度以及具有竞争力的 MOS/SMOS 分数,表明内容和说话人信息实现了有效解耦。
- 一拍语音转换实验表明,后期 RVQ 层的信息编码了说话人特征,能够实现可控的 VC 性能。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。