[论文解读] STaR-GATE: Teaching Language Models to Ask Clarifying Questions
STaR-GATE 微调语言模型,以提出更好的澄清性问题来引出用户偏好;经过两轮迭代,其回答在与初始模型的比较中赢得了 72%。
When prompting language models to complete a task, users often leave important aspects unsaid. While asking questions could resolve this ambiguity (GATE; Li et al., 2023), models often struggle to ask good questions. We explore a language model's ability to self-improve (STaR; Zelikman et al., 2022) by rewarding the model for generating useful questions-a simple method we dub STaR-GATE. We generate a synthetic dataset of 25,500 unique persona-task prompts to simulate conversations between a pretrained language model-the Questioner-and a Roleplayer whose preferences are unknown to the Questioner. By asking questions, the Questioner elicits preferences from the Roleplayer. The Questioner is iteratively finetuned on questions that increase the probability of high-quality responses to the task, which are generated by an Oracle with access to the Roleplayer's latent preferences. After two iterations of self-improvement, the Questioner asks better questions, allowing it to generate responses that are preferred over responses from the initial model on 72% of tasks. Our results indicate that teaching a language model to ask better questions leads to better personalized responses.
研究动机与目标
- 在用户–语言模型交互中明确任务模糊性及偏好引出需求的动机与定义。
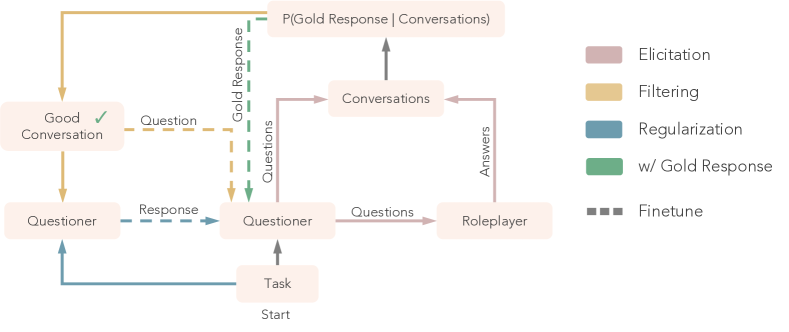
- 将 STaR-GATE 作为一个结合引出与自我对话循环的迭代自我改进框架引入。
- 创建用于训练的 persona-task 提示和黄金回复的合成数据集。
- 证明在引出的问题和自生回复上进行微调可提升下游回复质量。
提出的方法
- 使用具备 persona 访问权限的 Oracle 生成 25,500 条带黄金回复的 persona-task 合成数据集。
- 模拟 Questioner–Roleplayer 对话,通过定向问题引出用户偏好。
- 基于 Questioner 的提示和 Roleplayer 的偏好对黄金回复的对数概率定义奖励。
- 在最佳对话和相应模型回复上对 Questioner 进行微调(Expert Iteration 风格)。
- 通过在训练中加入前一轮的回复来正则化,以防止分布漂移。

实验结果
研究问题
- RQ1当用户偏好未知时,语言模型是否能够学习提出信息熵信息论层面的提问以提升任务表现?
- RQ2通过引出实现的迭代自我改进,是否能提升黄金回复的似然性与实际任务表现?
- RQ3纳入自生成回复与正则化如何影响学习稳定性及输出的真实感?
- RQ4收益是否在训练 persona 以外的不同 Roleplayer 中也具备泛化性?
- RQ5哪些消融实验揭示正则化和在回复 vs. 提问上的训练的必要性?
主要发现
- 以提问为中心的微调在各轮中提升黄金回复的对数概率。
- STaR-GATE 在两轮迭代后对初始模型的胜率达到 72%。
- 该方法对训练 persona 之外的 roleplayers 具备一定的泛化性(部分鲁棒性已显示)。
- 带有自生成回复的正则化对于防止遗忘如何回答以及避免幻觉至关重要。
- 消融研究表明仅在问题上训练会降级性能,而在黄金回复上训练可能导致输出不现实。
- 以回复进行正则化的 STaR-GATE 效果优于仅在问题或仅在黄金回复上训练的版本。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。