[论文解读] SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
SWE-bench 是一个基于执行的基准,评估对 2,294 个需要进行仓库级补丁的真实世界 GitHub 问题;最先进的模型仅能解决最简单的任务,在 oracle 检索下 Claude 2 为 4.8%、GPT-4 为 1.7%,在 BM25 上下文检索时甚至更糟。
Language models have outpaced our ability to evaluate them effectively, but for their future development it is essential to study the frontier of their capabilities. We find real-world software engineering to be a rich, sustainable, and challenging testbed for evaluating the next generation of language models. To this end, we introduce SWE-bench, an evaluation framework consisting of $2,294$ software engineering problems drawn from real GitHub issues and corresponding pull requests across $12$ popular Python repositories. Given a codebase along with a description of an issue to be resolved, a language model is tasked with editing the codebase to address the issue. Resolving issues in SWE-bench frequently requires understanding and coordinating changes across multiple functions, classes, and even files simultaneously, calling for models to interact with execution environments, process extremely long contexts and perform complex reasoning that goes far beyond traditional code generation tasks. Our evaluations show that both state-of-the-art proprietary models and our fine-tuned model SWE-Llama can resolve only the simplest issues. The best-performing model, Claude 2, is able to solve a mere $1.96$% of the issues. Advances on SWE-bench represent steps towards LMs that are more practical, intelligent, and autonomous.
研究动机与目标
- 评估大语言模型编辑真实世界代码库以通过生成补丁文件来解决 GitHub 问题的能力。
- 提供一个具有多样化、跨多个 Python 仓库的长上下文代码编辑任务的具有挑战性、最新的基准。
- 提供一个可重复的评估框架,通过现有测试套件进行基于执行的验证。
- 发布训练数据和微调模型,以促进开放开发,推动更自主的代码编辑式语言模型的发展。
提出的方法
- 从 12 个受欢迎的 Python 仓库构建 SWE-bench,通过将 issue 与合并修改测试并解决问题的 PR 进行关联来实现。
- 通过一个 3 阶段管线(仓库抓取、属性筛选、基于执行的筛选)筛选出 2,294 个任务实例。
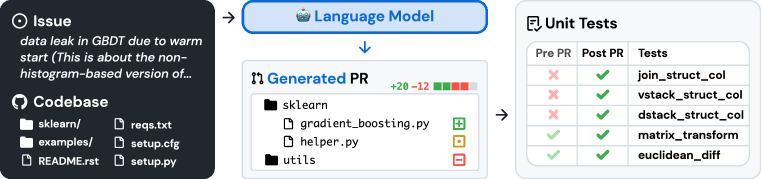
- 将任务表示为 issue 文本加上代码库快照;模型生成仓库级的补丁文件。
- 通过应用补丁并运行仓库测试来评估编辑;以通过率作为主要指标。
- 探索检索策略(BM25 稀疏检索和 oracle 检索),在长代码库中提供相关上下文。
- 在 37 个仓库的 19,000 个额外 issue-PR 对上对 SWE-Llama 7b/13b 进行 LoRA 微调,以创建一个有竞争力的开源基线模型。
实验结果
研究问题
- RQ1当前的语言模型在通过为大型代码库生成补丁来解决真实世界的软件工程问题方面有多大能力?
- RQ2上下文检索策略和补丁生成格式对模型性能有何影响?
- RQ3对开源模型进行微调能否缩小与专有模型在仓库级代码编辑上的差距?
- RQ4任务难度、上下文长度和仓库特征如何影响 SWE-bench 上的模型性能?
主要发现
- 多数最先进的模型无法解决超过最简单任务;在 oracle 检索下 Claude 2 获得 4.8%,GPT-4 获得 1.7%。
- 基于 BM25 的检索进一步降低性能(Claude 2 降至 1.96%)。
- 微调的 SWE-Llama 模型(7b/13b)表现有限,且对上下文分布的变化敏感。
- 模型的编辑通常比 Gold 补丁更短更简单,编辑的行数/文件数较少。
- 增大上下文长度可能降低性能,因为在大上下文中定位相关编辑更困难。
- 即使提供了 oracle 检索的上下文,模型也很少生成正确、格式良好的补丁文件;大约一半生成的补丁比 Gold 短,且较少编辑多个文件。

更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。