[论文解读] Testing the General Deductive Reasoning Capacity of Large Language Models Using OOD Examples
本论文提出 PrOntoQA-OOD,一种可编程的合成数据集,用于测试 LLMs 的一般推理能力,涵盖规则多样性、证明深度、宽度和组合性,并评估超出上下文演示的 OOD 泛化。
Given the intractably large size of the space of proofs, any model that is capable of general deductive reasoning must generalize to proofs of greater complexity. Recent studies have shown that large language models (LLMs) possess some abstract deductive reasoning ability given chain-of-thought prompts. However, they have primarily been tested on proofs using modus ponens or of a specific size, and from the same distribution as the in-context examples. To measure the general deductive reasoning ability of LLMs, we test on a broad set of deduction rules and measure their ability to generalize to more complex proofs from simpler demonstrations from multiple angles: depth-, width-, and compositional generalization. To facilitate systematic exploration, we construct a new synthetic and programmable reasoning dataset that enables control over deduction rules and proof complexity. Our experiments on four LLMs of various sizes and training objectives show that they are able to generalize to compositional proofs. However, they have difficulty generalizing to longer proofs, and they require explicit demonstrations to produce hypothetical subproofs, specifically in proof by cases and proof by contradiction.
研究动机与目标
- 评估 LLMs 在超出其演示的更高复杂度证明上的泛化能力。
- 在超出肯准推理法则的多种推理规则下评估泛化。
- 考察基于合成世界模型生成的证明在深度、宽度和组合性方面的泛化。
- 确定上下文学习与监督学习在推理任务泛化中的影响。
提出的方法
- 创建 PrOntoQA-OOD,一种可编程的合成数据集,在 PrOntoQA 的基础上扩展多种推理规则并可控的证明深度与宽度。
- 将证明表示为树结构以量化深度(证明链长度)和宽度(每步的前提数量)。
- 通过递归过程将不同推理规则组合成子证明,从而生成组合性证明。
- 包含干扰项以防止捷径启发式,从而对推理步骤进行鲁棒评估。
- 对 CoT 输出进行语义解析为一阶逻辑,以验证每一步推理的有效性及与前提的接近度。
- 在分布内和分布外条件下,评估八-shot Chain-of-Thought 提示在 GPT-3.5、PaLM、LLaMA 和 FLAN-T5 上的表现。
实验结果
研究问题
- RQ1当以 CoT 演示为提示时,LLMs 能否学习到除 modus ponens 之外的一整套推理规则?
- RQ2LLMs 是否能对比演示中出现的证明更深更宽(深度/宽度泛化)及对组合性证明(一个证明中包含多条规则)进行泛化?
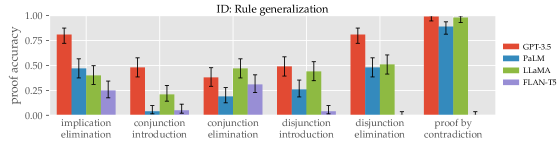
- RQ3在没有显式演示的情况下,LLMs 能在多大程度上对未见的推理规则(OOD 规则泛化)进行泛化?
- RQ4上下文学习与监督学习在实现一般推理能力方面有何差异?
- RQ5干扰项对 OOD 泛化和避免捷径解法的影响如何?
主要发现
- LLMs 可以利用 CoT 提示实现对组合性证明的泛化,尽管较长的证明仍具挑战性。
- 模型性能与规模不呈显著正相关;较小模型经过指令微调也能达到与更大模型相当的表现。
- LLMs 可以在没有显式演示的情况下使用若干推理规则,但某些规则(如析取法和反证法)在某些情形下需要演示。
- 在某些情境下,来自与测试样本不同分布的上下文演示,可能比来自同分布的演示更有助于组合性泛化。
- 干扰项可以降低某些模型的复制性启发式,但效果因规则和模型而异。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。