[论文解读] The Recent Advances in Automatic Term Extraction: A survey
对监督式术语抽取的综合综述,强调基于神经网络和 Transformer 的模型,并将其与传统的特征工程方法进行比较,讨论数据集、评估指标和挑战。
Automatic term extraction (ATE) is a Natural Language Processing (NLP) task that eases the effort of manually identifying terms from domain-specific corpora by providing a list of candidate terms. As units of knowledge in a specific field of expertise, extracted terms are not only beneficial for several terminographical tasks, but also support and improve several complex downstream tasks, e.g., information retrieval, machine translation, topic detection, and sentiment analysis. ATE systems, along with annotated datasets, have been studied and developed widely for decades, but recently we observed a surge in novel neural systems for the task at hand. Despite a large amount of new research on ATE, systematic survey studies covering novel neural approaches are lacking. We present a comprehensive survey of deep learning-based approaches to ATE, with a focus on Transformer-based neural models. The study also offers a comparison between these systems and previous ATE approaches, which were based on feature engineering and non-neural supervised learning algorithms.
研究动机与目标
- 在过去三十年里梳理与术语抽取相关的资源与公开可用语料库。
- 系统性评估基于深度学习的 ATE 方法,聚焦 Transformer 基于模型,与传统特征工程方法进行对比。
- 对 ATE 的评估指标进行分类,并分析直接评估与间接评估的方法。
- 识别多词术语与嵌套术语抽取的挑战及鲁棒性问题,并提出未来研究方向。
提出的方法
- 通过调研公开可用的单语与多语言语料库,识别并对 ATE 资源进行分类。
- 对监督 ATE 系统进行系统性综述,对比传统特征工程方法与神经网络方法。
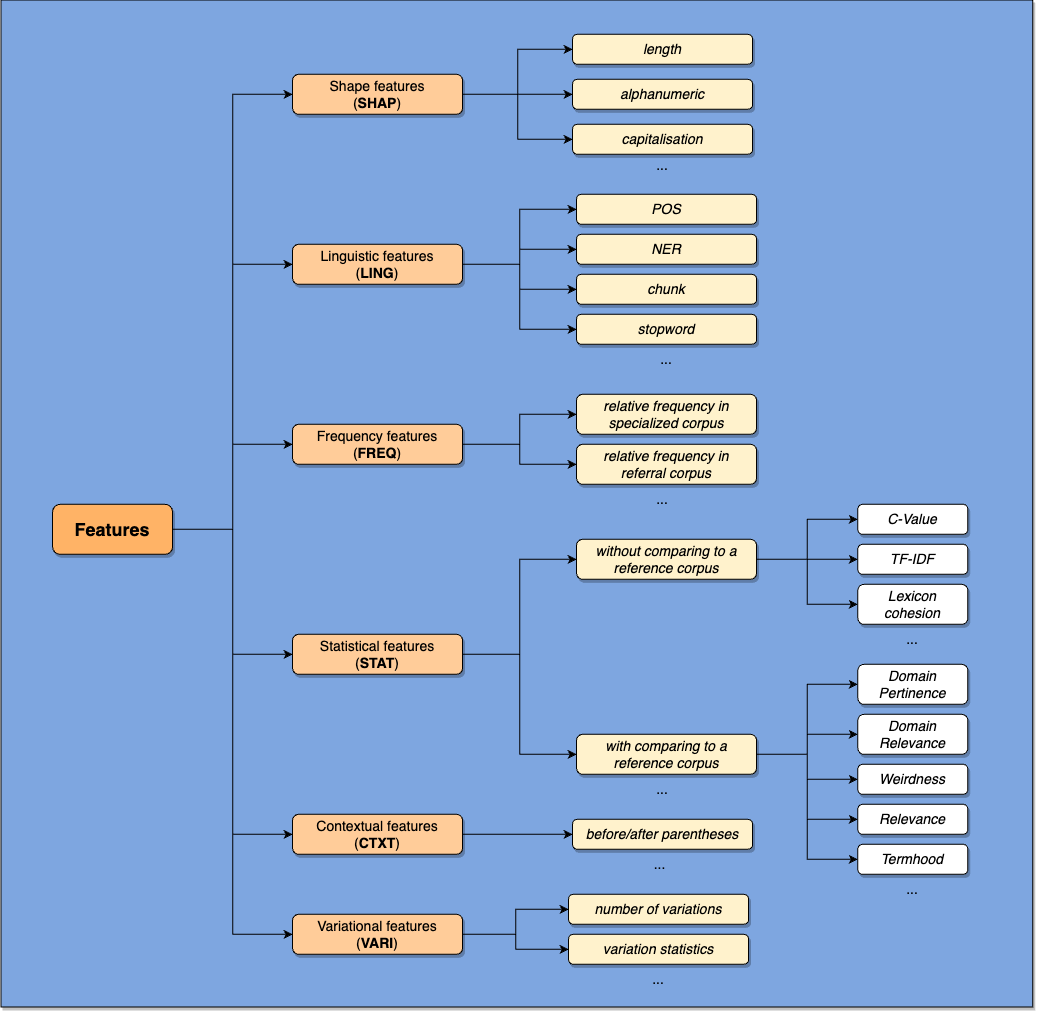
- 讨论用于 ATE 的嵌入表示(通用、领域特定、上下文表示)及其对性能的影响。
- 描述用于 ATE 的神经网络架构,包括序列/分类与序列到序列模型,以及它们在迁移学习范式中的定位。
- 总结评估实践并基于现有数据集和系统的洞见提出发展方向。
实验结果
研究问题
- RQ1有哪些公开可用的单语与多语言 ATE 数据集与语料库,它们如何随时间演变?
- RQ2基于 Transformer 的和其他神经 ATE 系统在性能与鲁棒性方面与传统特征工程方法相比如何?
- RQ3ATE 常用的评估指标和方法论有哪些,它们与下游任务有何关系?
- RQ4ATE 的主要仍存挑战,如多词与嵌套术语抽取,以及未来工作如何应对?
主要发现
- 神经网络和基于 Transformer 的方法在 ATE 中日益流行,且常常优于依赖手工特征的传统方法。
- 结合通用与领域特定知识的嵌入策略,以及上下文嵌入,提升了 ATE 的性能。
- 如 ACTER 等带有标注的多语言语料库为跨语言和跨领域的 ATE 提供了强有力的基准,便于更稳健的比较。
- 单语语料的标注方案与评估协议存在显著差异,给跨数据集比较带来困难。
- 评估实践包括直接评估(金标准、人工判断)和间接评估(下游任务),亟需标准化基准。
- 当前挑战包括准确捕捉多词和嵌套术语,以及在不同语言和领域中提升系统鲁棒性。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。