[论文解读] TIM: Teaching Large Language Models to Translate with Comparison
TIM 通过输出和偏好比较对比来微调开源 LLM 以进行翻译,提升翻译质量、零-shot 表现,以及在不同模型规模上的鲁棒性。
Open-sourced large language models (LLMs) have demonstrated remarkable efficacy in various tasks with instruction tuning. However, these models can sometimes struggle with tasks that require more specialized knowledge such as translation. One possible reason for such deficiency is that instruction tuning aims to generate fluent and coherent text that continues from a given instruction without being constrained by any task-specific requirements. Moreover, it can be more challenging for tuning smaller LLMs with lower-quality training data. To address this issue, we propose a novel framework using examples in comparison to teach LLMs to learn translation. Our approach involves presenting the model with examples of correct and incorrect translations and using a preference loss to guide the model's learning. We evaluate our method on WMT2022 test sets and show that it outperforms existing methods. Our findings offer a new perspective on fine-tuning LLMs for translation tasks and provide a promising solution for generating high-quality translations. Please refer to Github for more details: https://github.com/lemon0830/TIM.
研究动机与目标
- 提升开源 LLMs 的翻译质量,超越标准指令微调的动机。
- 通过新颖的比较机制,利用少量高质量翻译数据。
- 引入输出和偏好比较信号,以正则化和引导翻译学习。
- 评估 TIM 如何随模型规模扩展并对零-shot 翻译的泛化能力进行测试。
- 提供对推理策略和影响翻译质量的数据类型的洞见。
提出的方法
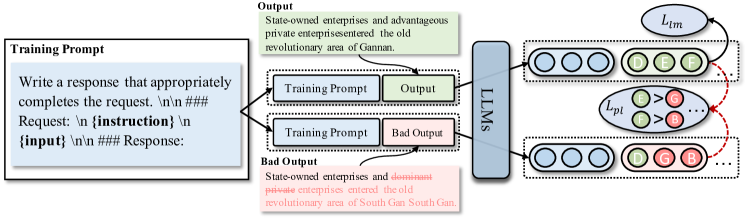
- 引入输出比较以学习对同一输入的不同指令的响应。
- 引入偏好比较损失以区分更好翻译与较差翻译。
- 增加一个逐字(token-level)偏好损失 L_pl 以对输出进行正则化(论文中给出 L_pl 公式)。
- 将 L_pl 与标准语言模型损失结合(L = L_lm + λ L_pl,λ = 1.0)。
- 构造三种用于比较的数据类型:顺序导向、词典导向和错误导向数据。
- 探索三种微调策略(LoRA、FixEmb、Full)以评估参数效率与性能。
- 在 WMT22 与 FLORES-200 上对 EN ⇄ DE 与 ZH ⇄ EN 进行评估,使用多种主干模型(如 BLOOMZ-7b-mt、LLaMA-2-7b/13b)。

实验结果
研究问题
- RQ1相比标准指令微调,基于比较的微调是否能提升开源 LLMs 的翻译质量?
- RQ2输出比较与偏好比较如何有助于减少幻觉并提高翻译的可信度?
- RQ3数据类型(顺序导向、词典导向、错误导向)对翻译质量和鲁棒性有何影响?
- RQ4TIM 的性能如何随模型规模以及语言方向变化,包含零-shot 设置?
- RQ5TIM 微调的模型是否在标准 MT 基准上具有竞争力或优于监督基线和多语言 MT 模型?
主要发现
- TIM 及其变体在 WMT22 与 FLORES-200 的四个翻译方向上,持续优于若干基线(如 Alpaca-*, MT-*, WMT22 获胜者).
- TIM-LLaMA-13b 在英文↔德语翻译中在无参考的情况下达到顶尖的质量评估表现。
- TIM 的改进对较小模型的效果更明显,表明与比较信号结合时具有更高的效率。
- TIM 的零-shot 多语言翻译能力相较于若干开源模型表现出色,在多数方向上接近 NLLB-3.3B,特别是在 Ja→En。
- 消融研究表明词典导向数据、输出比较以及基于 LM 的不良输出变体提供有意义的信号,而随机噪声效果较差。
- MT 指标评估显示 TIM-LLaMA-13b 与 TIM-BLOOMZ-7b 在不依赖参考的度量与 MQM 分数相关性方面可超越参考自由指标。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。