[论文解读] Towards Efficient Generative Large Language Model Serving: A Survey from Algorithms to Systems
本文综述高效服务生成式 LLM 的方法,涵盖从解码技术到硬件感知体系结构与量化等算法创新与系统优化,并勾勒出未来的研究方向。
In the rapidly evolving landscape of artificial intelligence (AI), generative large language models (LLMs) stand at the forefront, revolutionizing how we interact with our data. However, the computational intensity and memory consumption of deploying these models present substantial challenges in terms of serving efficiency, particularly in scenarios demanding low latency and high throughput. This survey addresses the imperative need for efficient LLM serving methodologies from a machine learning system (MLSys) research perspective, standing at the crux of advanced AI innovations and practical system optimizations. We provide in-depth analysis, covering a spectrum of solutions, ranging from cutting-edge algorithmic modifications to groundbreaking changes in system designs. The survey aims to provide a comprehensive understanding of the current state and future directions in efficient LLM serving, offering valuable insights for researchers and practitioners in overcoming the barriers of effective LLM deployment, thereby reshaping the future of AI.
研究动机与目标
- 提供对 LLM 服务与推理方面进展的全面概述。
- 按底层方法(算法性与系统性)对技术进行分类并分析其优缺点。
- 考察解码、体系结构设计、模型压缩、低位量化、并行计算、内存管理与内核优化。
- 汇总具代表性的 LLM 服务框架与基准,为未来研究和实践提供指引。
提出的方法
- 建立高效 LLM 服务方法的分类法,将算法创新与系统优化分开讨论。
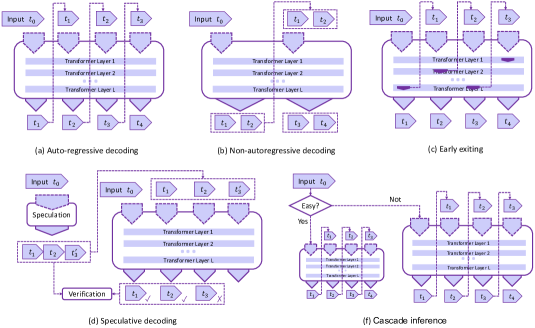
- 分析解码算法(非自回归解码、推测解码、早停、级联推理)及其权衡。
- 描述体系结构设计选项(配置缩减、注意力简化、激活共享、条件计算、循环单元)。
- 回顾模型压缩技术(知识蒸馏、剪枝)及其在 LLM 的适用性。
- 总结低位量化(QAT 与 PTQ)及其对推理的硬件影响。
- 讨论系统级优化,包括并行计算与内存管理,以实现高效部署。
实验结果
研究问题
- RQ1有哪些主要的算法级和系统级技术被提出以提升 LLM 服务的效率?
- RQ2解码策略、体系结构选择以及压缩/量化如何影响推理速度与资源使用?
- RQ3在跨硬件平台部署高效 LLM 推理时,面临的主要挑战与权衡是什么?
- RQ4未来 LLM 服务研究与系统设计最有前景的方向是什么?
主要发现
- 该综述提供了两部分的分类法:用于 LLM 服务的算法创新与系统优化。
- 所探讨的解码算法包括非自回归解码、推测解码、早停和级联推理,讨论了权衡与验证保证。
- 体系结构设计方法涵盖配置缩减、注意力简化、激活共享、条件计算和循环单元等以提高效率的选项。
- 模型压缩技术如知识蒸馏与剪枝在 LLM 推理中的适用性及实际收益被评估。
- 对低位量化(QAT 与 PTQ)及其对推理的硬件影响进行了分析,包括潜在的延迟与吞吐提升及缩放效应。
- 论文还讨论了并行计算、内存管理和内核优化等系统级策略,这些对将效率提升落地至关重要。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。