[论文解读] Transformer models: an introduction and catalog
tldr: 一本采用目录风格的综述,介绍 Transformer 的基础要点,并提供一个涵盖流行 Transformer 模型的综合目录,其中包括自监督和人类在环微调变体。
In the past few years we have seen the meteoric appearance of dozens of foundation models of the Transformer family, all of which have memorable and sometimes funny, but not self-explanatory, names. The goal of this paper is to offer a somewhat comprehensive but simple catalog and classification of the most popular Transformer models. The paper also includes an introduction to the most important aspects and innovations in Transformer models. Our catalog will include models that are trained using self-supervised learning (e.g., BERT or GPT3) as well as those that are further trained using a human-in-the-loop (e.g. the InstructGPT model used by ChatGPT).
研究动机与目标
- Motivate understanding of Transformer architecture and its impact across NLP and beyond.
- Provide a simple, comprehensive catalog of popular Transformer models and their core properties.
- Explain foundation vs fine-tuned models and the role of RLHF and human feedback in contemporary systems.
- Highlight the evolution, applications, and extensions of Transformer models across tasks and modalities.
提出的方法
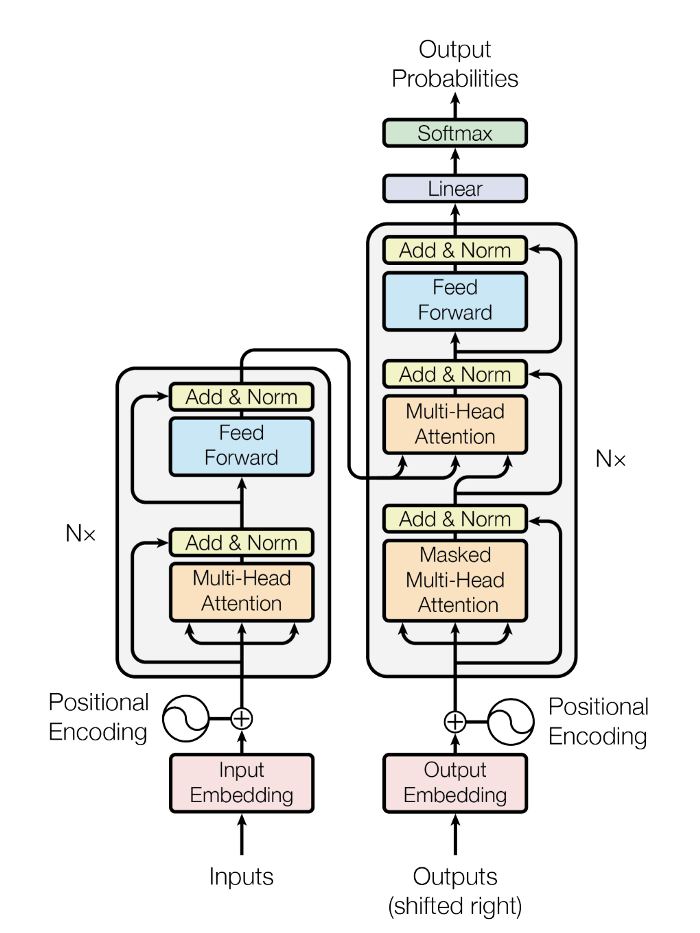
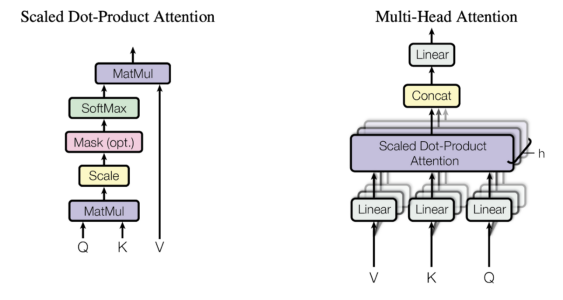
- Describe the encoder/decoder Transformer architecture and the attention mechanism.
- Classify models by pretraining architecture (encoder, decoder, or encoder-decoder) and by pretraining tasks (MLM, DAE, LM, etc.).
- Define and discuss foundation versus fine-tuned models and the role of RLHF in practice.
- Present a catalog table and family tree to trace model lineage and relationships.
- Provide a chronological timeline and an appendix catalog list detailing representative models with key attributes.
- Explain diffusion models in relation to Transformers and note their interoperability.
实验结果
研究问题
- RQ1What are the core architectural variants and pretraining objectives that define major Transformer models?
- RQ2How do foundation models differ from fine-tuned models in practice, and what role does RLHF play?
- RQ3What is the landscape and lineage of popular Transformer models up to the present, including multimodal and dialog agents?
- RQ4What are the main applications and trends driving Transformer model development across tasks and modalities?
主要发现
- Transformers enable parallel computation and long-range dependency learning via self-attention, enabling advancement beyond RNN/LSTM architectures.
- Foundation models trained with self-supervision can be adapted to a wide range of downstream tasks through fine-tuning or prompting.
- Human-in-the-loop techniques like RLHF have become central to aligning and improving dialog agents such as ChatGPT and related systems.
- The catalog identifies numerous models across families (e.g., BERT, GPT, BART, T5, BLOOM) with varied pretraining architectures and tasks.
- Diffusion models are related to but distinct from Transformers, though many diffusion approaches integrate Transformer backbones.
- The paper emphasizes the ecosystem around Transformers, including tooling, hardware accelerators, and open-source communities (e.g., HuggingFace) that accelerate adoption.
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。