[论文解读] Tulu 3: Pushing Frontiers in Open Language Model Post-Training
Tulu 3 提供了一个开放、完全披露的后训练方案,用于大语言模型,包括数据、代码和评估,并展示它在 70B 规模下通过 RLVR 及其他技术超越开源权重同行与对手的闭源模型。
Language model post-training is applied to refine behaviors and unlock new skills across a wide range of recent language models, but open recipes for applying these techniques lag behind proprietary ones. The underlying training data and recipes for post-training are simultaneously the most important pieces of the puzzle and the portion with the least transparency. To bridge this gap, we introduce Tulu 3, a family of fully-open state-of-the-art post-trained models, alongside its data, code, and training recipes, serving as a comprehensive guide for modern post-training techniques. Tulu 3, which builds on Llama 3.1 base models, achieves results surpassing the instruct versions of Llama 3.1, Qwen 2.5, Mistral, and even closed models such as GPT-4o-mini and Claude 3.5-Haiku. The training algorithms for our models include supervised finetuning (SFT), Direct Preference Optimization (DPO), and a novel method we call Reinforcement Learning with Verifiable Rewards (RLVR). With Tulu 3, we introduce a multi-task evaluation scheme for post-training recipes with development and unseen evaluations, standard benchmark implementations, and substantial decontamination of existing open datasets on said benchmarks. We conclude with analysis and discussion of training methods that did not reliably improve performance. In addition to the Tulu 3 model weights and demo, we release the complete recipe -- including datasets for diverse core skills, a robust toolkit for data curation and evaluation, the training code and infrastructure, and, most importantly, a detailed report for reproducing and further adapting the Tulu 3 approach to more domains.
研究动机与目标
- 定义一个完全开放的后训练框架,以缩小与专有方法之间的差距。
- 提供开放数据集、评估套件和训练方案,以实现可重复的大型 LLM 的后训练。
- 证明开放后训练可以超越最先进的开放模型,并达到某些闭源模型的能力。
- 引入并验证新的训练阶段与数据策略,以提高跨多任务的核心技能。
提出的方法
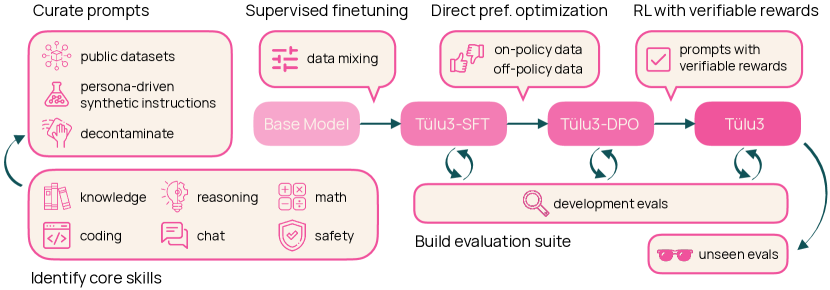
- 描述 Tulu 3 的数据、评估与代码生态系统。
- 提出一个包含 SFT、直接偏好优化(DPO)和可验证奖励的强化学习(RLVR)的多阶段训练方案。
- 开发广泛的去污染和评估工具,以衡量并指导进展。
- 使用按策略的偏好数据与可验证的奖励信号来优化技能发展(推理、数学、编码等)。
- 以开放与闭源模型进行基准测试,确立相对性能。
实验结果
研究问题
- RQ1开放、完全披露的后训练方案是否能超越同等规模的在元数据开放权重的后训练模型?
- RQ2RLVR 是否在数学和精确指令执行等技能方面提供可验证的改进?
- RQ3哪些数据、方法学与评估实践最可靠地提高跨开发阶段与未见任务的核心技能?
- RQ4去污染、合成数据与偏好数据结合开放基础设施在多大程度上能匹配闭源模型能力?
- RQ5完全开放的后训练流水线有哪些实际设计考虑与局限性?
主要发现
- Tulu 3 模型超越同等规模的开权最先进基线,如 Llama 3.1 Instruct、Qwen2.5 Instruct 和 Mistral-Instruct。
- 在 70B 规模下,Tulu 3 与某些闭源模型的能力相当,如 Claude 3.5 Haiku 与 GPT-4o mini。
- Tulu 3 流水线结合了 SFT、DPO 与 RLVR,在核心技能方面实现了强劲的表现。
- 广泛的去污染和强健的评估框架提升了基准结果的可靠性。
- 发布包含模型权重、数据、代码以及端到端的配方,便于复现与适应。
- RLVR 中的新奖励目标确保奖励可验证,指导技能特定的改进。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。