[论文解读] UltraFeedback: Boosting Language Models with Scaled AI Feedback
UltraFeedback 创建一个大规模、细粒度的偏好与批评数据集,以提升开源 LLM 的 RLHF,支持新的奖励与批评模型,并通过 RLHF 和 best-of-n 策略显示性能提升。
Learning from human feedback has become a pivot technique in aligning large language models (LLMs) with human preferences. However, acquiring vast and premium human feedback is bottlenecked by time, labor, and human capability, resulting in small sizes or limited topics of current datasets. This further hinders feedback learning as well as alignment research within the open-source community. To address this issue, we explore how to go beyond human feedback and collect high-quality extit{AI feedback} automatically for a scalable alternative. Specifically, we identify extbf{scale and diversity} as the key factors for feedback data to take effect. Accordingly, we first broaden instructions and responses in both amount and breadth to encompass a wider range of user-assistant interactions. Then, we meticulously apply a series of techniques to mitigate annotation biases for more reliable AI feedback. We finally present extsc{UltraFeedback}, a large-scale, high-quality, and diversified AI feedback dataset, which contains over 1 million GPT-4 feedback for 250k user-assistant conversations from various aspects. Built upon extsc{UltraFeedback}, we align a LLaMA-based model by best-of-$n$ sampling and reinforcement learning, demonstrating its exceptional performance on chat benchmarks. Our work validates the effectiveness of scaled AI feedback data in constructing strong open-source chat language models, serving as a solid foundation for future feedback learning research. Our data and models are available at https://github.com/thunlp/UltraFeedback.
研究动机与目标
- 解决开源偏好数据在 RLHF 中的稀缺性。
- 构建一个大规模、多样化且精细注释的偏好数据集,包含文本反馈。
- 使用 UltraFeedback 训练开源奖励模型(UltraRM)和批评模型(UltraCM)。
- 通过 best-of-n 抽样和基于 PPO 的 RLHF 展示开源 LLM 的改进。
- 为未来的 RLHF 研究提供可重复的数据构建和模型训练流程。
提出的方法
- 从多源采样多样化的指令和模型完成,以创建对比数据。
- 使用 GPT-4 为每个完成生成标量偏好和详细文本批评。
- 使用二元排序损失训练 UltraRM,以在成对比较中选择偏好完成。
- 在 UltraRM 作为奖励模型的前提下,使用 best-of-n 采样和 PPO 微调 UltraLM。
- 在 UltraFeedback 的文本批评上训练 UltraCM,以实现自动批评生成。
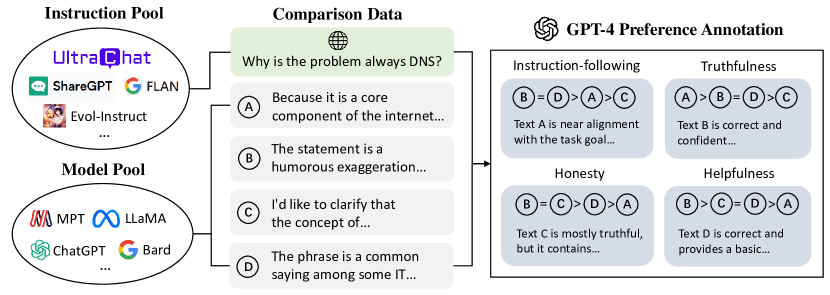
实验结果
研究问题
- RQ1UltraFeedback 能否产生高质量、细粒度的偏好数据,并推广到开源模型?
- RQ2基于 UltraFeedback 训练的奖励模型是否在标准基准上优于现有的开源基线?
- RQ3通过 PPO 的 UltraRM 的 RLHF 是否比其他方法更能提升开源聊天模型?
- RQ4随附的批评模型 UltraCM 是否能够在各任务中提供有用的高质量反馈?
主要发现
- 使用 UltraFeedback 训练的 UltraRM 变体在多个基准上优于若干开源奖励模型。
- 使用 UltraRM 奖励的 best-of-n 采样在无需额外训练的情况下显著提升响应质量。
- 在 UltraFeedback 下对 UltraLM-13B 进行 PPO 微调,在公开基准上获得显著性能提升。
- UltraCM 提供的详细高质量文本批评在许多任务中接近某些封闭或更大规模对手的质量。
- 该数据集支持可重复的奖励建模和批评建模工作流,用于开源 RLHF 研究。

更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。