[论文解读] Understanding Emergent In-Context Learning from a Kernel Regression Perspective
提出在 transformers 中的上下文学习源自对示例的核回归,理论与经验分析将注意力与样本标签的核样式权重联系起来并支撑此观点。
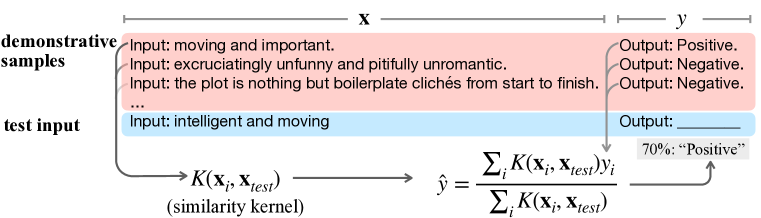
Large language models (LLMs) have initiated a paradigm shift in transfer learning. In contrast to the classic pretraining-then-finetuning procedure, in order to use LLMs for downstream prediction tasks, one only needs to provide a few demonstrations, known as in-context examples, without adding more or updating existing model parameters. This in-context learning (ICL) capability of LLMs is intriguing, and it is not yet fully understood how pretrained LLMs acquire such capabilities. In this paper, we investigate the reason why a transformer-based language model can accomplish in-context learning after pre-training on a general language corpus by proposing a kernel-regression perspective of understanding LLMs' ICL bahaviors when faced with in-context examples. More concretely, we first prove that Bayesian inference on in-context prompts can be asymptotically understood as kernel regression $\hat y = \sum_i y_i K(x, x_i)/\sum_i K(x, x_i)$ as the number of in-context demonstrations grows. Then, we empirically investigate the in-context behaviors of language models. We find that during ICL, the attention and hidden features in LLMs match the behaviors of a kernel regression. Finally, our theory provides insights into multiple phenomena observed in the ICL field: why retrieving demonstrative samples similar to test samples can help, why ICL performance is sensitive to the output formats, and why ICL accuracy benefits from selecting in-distribution and representative samples. Code and resources are publicly available at https://github.com/Glaciohound/Explain-ICL-As-Kernel-Regression.
研究动机与目标
- Motivate and understand why LLMs show in-context learning after pre-training on large general corpora.
- Propose a kernel regression perspective as a theoretical explanation for ICL.
- Link attention mechanisms in Transformers to kernel regression computations.
- Empirically verify kernel-regression-like behavior in LLM attention and intermediate features.
提出的方法
- Formulate in-context learning as Bayesian inference that converges to kernel regression with a kernel defined from pre-training dynamics (K(x, x')).
- Derive a theorem showing the Bayesian posterior on in-context prompts approaches a kernel-regression predictor as the number of demonstrations grows.
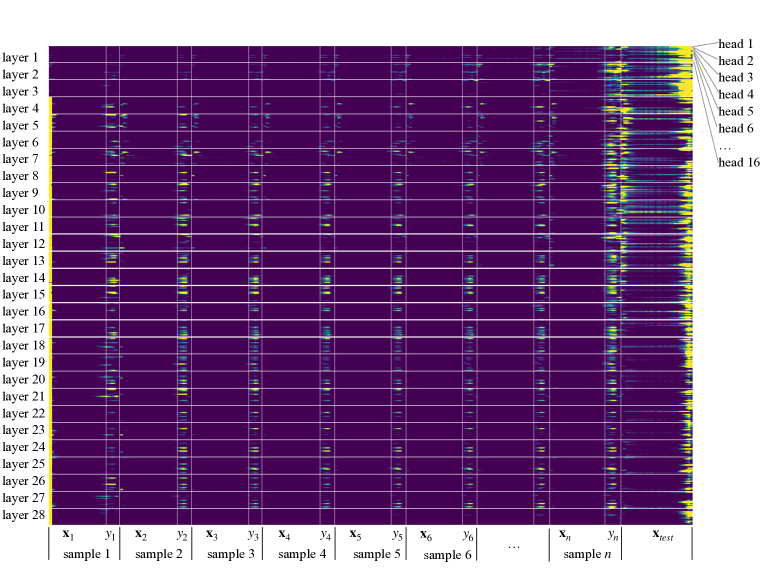
- Empirically analyze GPT-J-6B to inspect attention distributions, reconstruct ICL predictions from attention, and probe intermediate features for kernel-regression signals.
- Compare kernel-regression-based reconstruction with task-specific heads and sentence-encoder baselines.
- Demonstrate alignment between attention weights, sample labels, and predicted outputs in multiple layers.
实验结果
研究问题
- RQ1Does Bayesian inference on in-context prompts converge to kernel regression as the number of demonstrations increases?
- RQ2Do LLM attention patterns during ICL reflect kernel-regression-like weighting of in-context samples?
- RQ3Where in the model are features that encode kernel-regression information stored and how do they contribute to predictions?
- RQ4Can kernel-regression-based reconstruction match actual ICL predictions and how do demonstrations influence performance?
- RQ5What explains phenomena like retrieval of similar samples and sensitivity to label formats in ICL?
主要发现
- Theoretical result: Bayesian inference on in-context prompts converges to a kernel-regression form as the number of demonstrations grows.
- Attention distributions during ICL concentrate on sample labels and can reconstruct predictions with high accuracy (up to 89.2% in some heads).
- Some middle-layer heads (layers ~18–21) show kernel-regression-like behavior and can predict outputs using kernel-weighted label information.
- The similarity kernel aligns with attention-based weighting, linking semantic representations to kernel similarities.
- Reconstructed kernel-regression predictions using head features achieve comparable accuracy to ICL and to kernel methods on several tasks (sst2, mnli, etc.).
- Retrieving demonstrations similar to the test input improves ICL by effectively narrowing the kernel bandwidth and reducing bias.
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。