[论文解读] Understanding LLMs: A Comprehensive Overview from Training to Inference
本论文综述了 LLM 训练与推理的发展,覆盖数据预处理、架构、提示学习,以及向成本高效解决方案的部署趋势。
The introduction of ChatGPT has led to a significant increase in the utilization of Large Language Models (LLMs) for addressing downstream tasks. There's an increasing focus on cost-efficient training and deployment within this context. Low-cost training and deployment of LLMs represent the future development trend. This paper reviews the evolution of large language model training techniques and inference deployment technologies aligned with this emerging trend. The discussion on training includes various aspects, including data preprocessing, training architecture, pre-training tasks, parallel training, and relevant content related to model fine-tuning. On the inference side, the paper covers topics such as model compression, parallel computation, memory scheduling, and structural optimization. It also explores LLMs' utilization and provides insights into their future development.
研究动机与目标
- 解释大型语言模型从统计方法到 transformer-based 架构的演变,以及 LLMs 的兴起。
- 总结用于扩展到十亿级参数的训练数据来源、预处理和架构选择。
- 讨论提示学习、微调和对齐方法,作为全量再训练的高效替代方案。
- 评审旨在降低成本、提升可扩展性的推理、部署与优化技术。
提出的方法
- 回顾并综合历史与当代的 LLM 训练技术、数据来源和预处理方法。
- 解释 transformer-based 架构(encoder-decoder 和 decoder-only)及其在 LLM 规模扩张中的作用。
- 描述提示学习范式,包括模板、verbalizers 和学习策略。
- 综述推理和部署技术,如模型压缩、内存调度和结构优化。

实验结果
研究问题
- RQ1用于训练大型语言模型的关键数据来源和预处理步骤有哪些?
- RQ2基于 transformer 的架构如何支撑 LLMs,以及主要的训练范式(预训练、微调、提示)及其权衡?
- RQ3哪些提示学习技术和模板在不进行全量模型再训练的情况下提升任务性能?
- RQ4哪些推理与部署策略能够实现大规模使用 LLMs 的成本效益?
- RQ5LLM 训练与部署的未来方向与待解决的挑战有哪些?
主要发现
- LLMs 是建立在带有 encoder-decoder 或 decoder-only 配置的 transformer 架构之上。
- 通过使用模板和 verbalizers,提示学习提供了全量微调的高效替代方案。
- 数据预处理包括过滤、去重、隐私清洗以及毒性/偏见缓解,以提高安全性与质量。
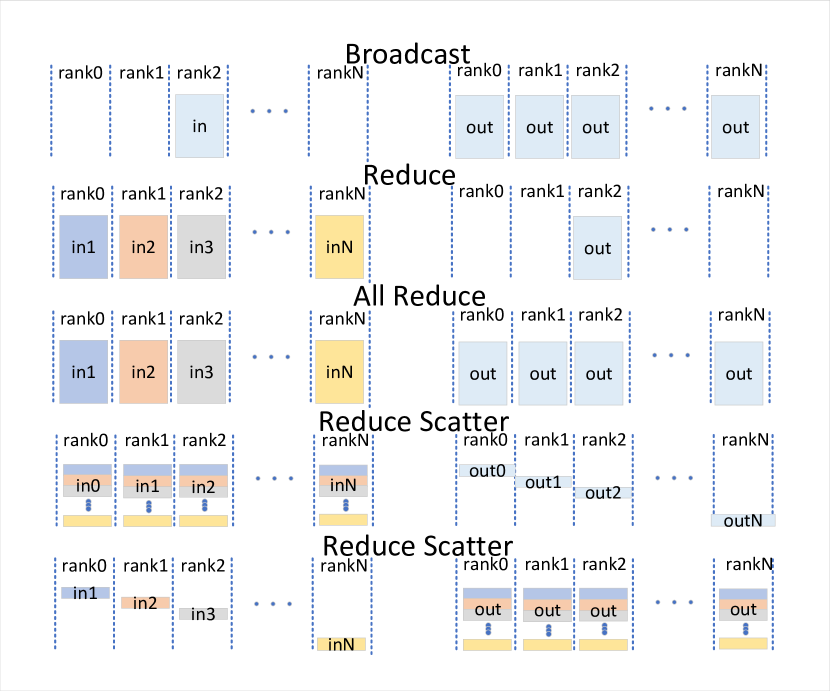
- 推理与部署的重点是模型压缩、并行计算、内存调度和结构优化,以降低成本。
- 本文讨论了向低成本的 LLM 训练与部署发展趋势。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。