[论文解读] Unifying (Machine) Vision via Counterfactual World Modeling
本论文提出 Counterfactual World Modeling (CWM),一个统一的、无监督的视觉框架,使用结构化掩蔽和反事实提示以零样本方式推导多种视觉计算(例如关键点、光流、遮挡、分割、深度)。
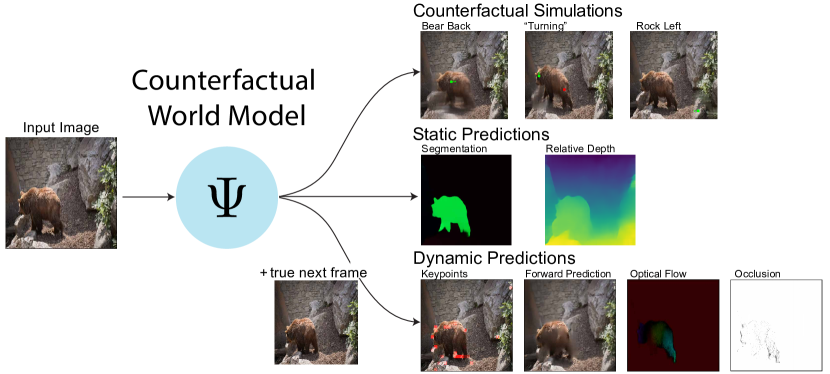
Leading approaches in machine vision employ different architectures for different tasks, trained on costly task-specific labeled datasets. This complexity has held back progress in areas, such as robotics, where robust task-general perception remains a bottleneck. In contrast, "foundation models" of natural language have shown how large pre-trained neural networks can provide zero-shot solutions to a broad spectrum of apparently distinct tasks. Here we introduce Counterfactual World Modeling (CWM), a framework for constructing a visual foundation model: a unified, unsupervised network that can be prompted to perform a wide variety of visual computations. CWM has two key components, which resolve the core issues that have hindered application of the foundation model concept to vision. The first is structured masking, a generalization of masked prediction methods that encourages a prediction model to capture the low-dimensional structure in visual data. The model thereby factors the key physical components of a scene and exposes an interface to them via small sets of visual tokens. This in turn enables CWM's second main idea -- counterfactual prompting -- the observation that many apparently distinct visual representations can be computed, in a zero-shot manner, by comparing the prediction model's output on real inputs versus slightly modified ("counterfactual") inputs. We show that CWM generates high-quality readouts on real-world images and videos for a diversity of tasks, including estimation of keypoints, optical flow, occlusions, object segments, and relative depth. Taken together, our results show that CWM is a promising path to unifying the manifold strands of machine vision in a conceptually simple foundation.
研究动机与目标
- 为视觉领域提出一种基础模型方法,类比语言模型的零样本多功能性。
- 开发一个无监督、统一的预测模型,通过结构化掩蔽学习场景结构与动力学。
- 通过反事实提示实现通用任务接口,在无需带标签数据的情况下推导出多种视觉计算。
- 展示如何通过反事实输入提取并操控场景动力学的计数与几何信息。
提出的方法
- 通过使用结构化掩蔽揭示第一帧的大部分以及第二帧的一小部分,将外观从动态中分解出来,训练一个时序因式分解的掩蔽预测器。
- 通过对真实输入与修改后的输入(反事实)进行比较,利用反事实提示推导多种视觉计算。
- 将关键点形式化为最大化重建清晰度的补丁,使其能够自举推导出其他表示。
- 证明光流、遮挡、可移动对象分割和相对深度可以作为预测器的导数或反事实得到。
- 扩展掩蔽方案与条件设定(如头部运动、多帧掩蔽)以丰富表示和任务。
- 解释模型的反事实导数如何提供高效的零样本任务接口。
实验结果
研究问题
- RQ1一个单一的无监督视觉模型是否能够通过结构化掩蔽学习核心场景结构和动力学?
- RQ2通过反事实提示是否可以将预测转化为多任务的零样本解决方案?
- RQ3如何从统一的预测器中推导出光流、遮挡、分割和深度?
- RQ4在提取多样化视觉表示方面,自举与导数的作用为何?
- RQ5掩蔽策略的变异如何影响学到的表示和任务覆盖?
主要发现
- 一个时序因式分解的掩蔽预测器学会了将外观从动力学中分离。
- 反事实提示使同一模型具备对多种视觉计算的零样本访问能力。
- 光流和遮挡可以通过预测器的导数和反事实扰动得到。
- 关键点作为最能降低重建误差的补丁出现,便于进行对象级分析。
- 该框架在以基础模型风格的视觉方法中统一了若干经典视觉概念。

更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。