[论文解读] User-LLM: Efficient LLM Contextualization with User Embeddings
User-LLM 将多模态用户交互嵌入到紧凑的嵌入中,并通过交叉注意力将它们引入到 LLMs,实现高效的长上下文个性化,而无需对整个 LLM 进行再训练。
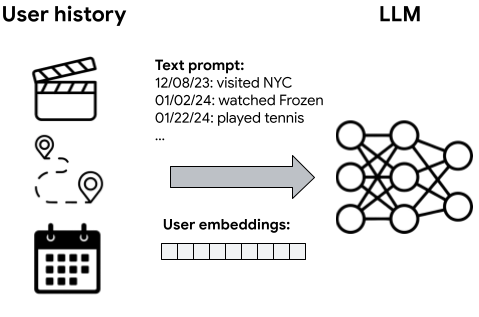
Large language models (LLMs) have achieved remarkable success across various domains, but effectively incorporating complex and potentially noisy user timeline data into LLMs remains a challenge. Current approaches often involve translating user timelines into text descriptions before feeding them to LLMs, which can be inefficient and may not fully capture the nuances of user behavior. Inspired by how LLMs are effectively integrated with images through direct embeddings, we propose User-LLM, a novel framework that leverages user embeddings to directly contextualize LLMs with user history interactions. These embeddings, generated by a user encoder pretrained using self-supervised learning on diverse user interactions, capture latent user behaviors and interests as well as their evolution over time. We integrate these user embeddings with LLMs through cross-attention, enabling LLMs to dynamically adapt their responses based on the context of a user's past actions and preferences. Our approach achieves significant efficiency gains by representing user timelines directly as embeddings, leading to substantial inference speedups of up to 78.1X. Comprehensive experiments on MovieLens, Amazon Review, and Google Local Review datasets demonstrate that User-LLM outperforms text-prompt-based contextualization on tasks requiring deep user understanding, with improvements of up to 16.33%, particularly excelling on long sequences that capture subtle shifts in user behavior. Furthermore, the incorporation of Perceiver layers streamlines the integration between user encoders and LLMs, yielding additional computational savings.
研究动机与目标
- 通过利用来自多样化交互的压缩用户表示来推动个性化的 LLM。
- 提出一个两阶段框架:(1) 预训练一个用户编码器以生成嵌入;(2) 通过跨注意力或软提示将嵌入整合到 LLM 中。
- 展示在跨数据集的长序列和多模态数据上的效率与可扩展性。
- 将基于嵌入的个性化与文本提示基线和完整微调进行比较,包括参数高效的训练策略。
提出的方法
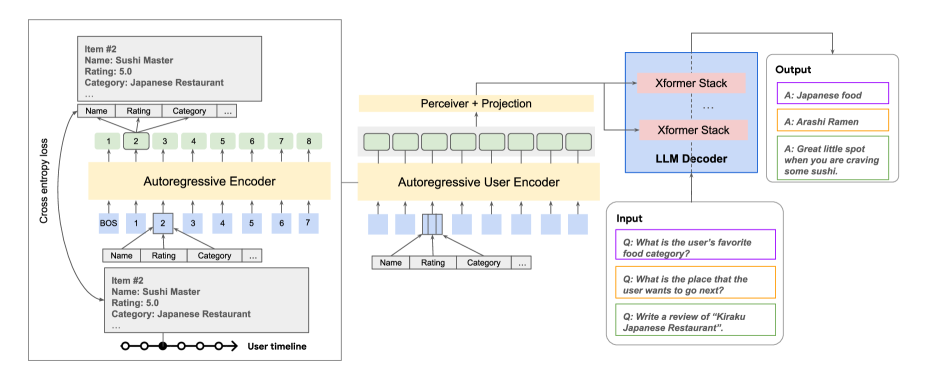
- 在多模态用户历史上训练一个基于 Transformer 的自回归用户编码器,以为每个事件产生密集嵌入。
- 将来自两种或多种模态的嵌入融合为一个用户的单一嵌入序列。
- 通过跨注意力(或软提示)将用户嵌入与 LLM 集成,以调控生成和预测。
- 通过 Perceiver 层对嵌入进行压缩,降低 LLM 的注意力负载以提高效率。
- 探索四种训练策略:Full finetune、Enc(冻结 LLM)、LoRA 和 Proj(冻结 LLM 和编码器)。
- 以 PaLM-2 XXS 作为 LLM,使用 6 层、128 维的 Transformer 作为用户编码器;研究跨注意力与软提示融合的效果。
实验结果
研究问题
- RQ1是否能通过从多模态交互中提炼的用户嵌入比文本提示更高效地提升 LLM 个性化?
- RQ2跨注意力与软提示融合在将用户嵌入整合到 LLMs 中的效果有何差异?
- RQ3在使用用户嵌入与 Perceiver 压缩来处理长历史时,FLOPs 和上下文长度方面有哪些效率提升?
- RQ4预训练的用户编码器是否能很好泛化到下一项预测之外的任务,如风格/类型预测与文本生成(评论撰写)?
- RQ5不同训练策略(Full、Enc、LoRA、Proj)对性能和参数效率有何影响?
主要发现
| 数据集 | Rec | Baseline | User-LLM | MovieLens20M @1 | MovieLens20M @5 | MovieLens20M @10 | Google Review @1 | Google Review @5 | Google Review @10 | Amazon Review @1 | Amazon Review @5 | Amazon Review @10 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MovieLens20M | @1 | 0.044 | 0.038 | 0.054 | ||||||||
| MovieLens20M | @5 | 0.135 | 0.135 | 0.164 | ||||||||
| MovieLens20M | @10 | 0.206 | 0.158 | 0.243 | ||||||||
| Google Review | @1 | 0.005 | 0.005 | 0.015 | ||||||||
| Google Review | @5 | 0.012 | 0.019 | 0.052 | ||||||||
| Google Review | @10 | 0.023 | 0.033 | 0.071 | ||||||||
| Amazon Review | @1 | 0.021 | 0.034 | 0.037 | ||||||||
| Amazon Review | @5 | 0.026 | 0.051 | 0.047 | ||||||||
| Amazon Review | @10 | 0.031 | 0.062 | 0.051 |
- User-LLM 在 MovieLens 和 Google Local Review 的下一项预测上优于非 LLM 基线;Amazon Review 更偏好 Bert4Rec,突出数据集稀疏性效应。
- 基于嵌入的上下文处理使 LLM 能够处理固定长度的提示(32 个标记),无论输入序列长度如何,相较于文本提示基线实现了显著的 FLOPs 下降(最高 78.1 倍)。
- 预训练的用户编码器在各任务上都相对于随机初始化的编码器提供一致的增益。
- 跨注意力融合通常优于软提示融合,尤其是在评论生成任务中。
- 仅微调编码器和投影层(Enc)即可在比全面微调少得多的可训练参数下实现有竞争力的性能,同时保留 LLM 知识。
- 基于 Perceiver 的压缩将嵌入标记数从 50 降至 16,同时几乎不损失性能,提升推理效率。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。