[论文解读] Using Large Language Models to Generate JUnit Tests: An Empirical Study
本研究评估 Codex、GPT-3.5-Turbo 与 StarCoder 在 Java 的零样本 JUnit5 测试生成中的表现,分析编译、正确性、覆盖率、测试异味以及在 HumanEval 与 SF110 基准上的表现,以及不同上下文风格的影响。
A code generation model generates code by taking a prompt from a code comment, existing code, or a combination of both. Although code generation models (e.g., GitHub Copilot) are increasingly being adopted in practice, it is unclear whether they can successfully be used for unit test generation without fine-tuning for a strongly typed language like Java. To fill this gap, we investigated how well three models (Codex, GPT-3.5-Turbo, and StarCoder) can generate unit tests. We used two benchmarks (HumanEval and Evosuite SF110) to investigate the effect of context generation on the unit test generation process. We evaluated the models based on compilation rates, test correctness, test coverage, and test smells. We found that the Codex model achieved above 80% coverage for the HumanEval dataset, but no model had more than 2% coverage for the EvoSuite SF110 benchmark. The generated tests also suffered from test smells, such as Duplicated Asserts and Empty Tests.
研究动机与目标
- 评估零样本 LLM 在为 Java 类生成 JUnit 测试方面的表现。
- 检查不同上下文输入(如 JavaDocs、方法签名)对测试生成性能的影响。
- 将 LLM 生成的测试在编译、正确性、覆盖率和异味指标方面与 Evosuite 进行比较。
- 描述在 LLM 生成的测试中常见的测试异味及其盛行程度。
- 讨论使用代码生成模型进行测试驱动开发的影响。
提出的方法
- 使用三种 LLM(Codex、GPT-3.5-Turbo、StarCoder)为 Java HumanEval 数据集和 SF110 基准中的 MUTs 生成 JUnit5 测试。
- 创建包含被测类及所需的 JUnit 导入的提示与上下文,为每个可测试的方法生成一个测试文件。
- 对生成的测试进行启发式修正以解决编译问题,并衡量修正后的编译率。
- 使用 JaCoCo 对测试进行逐行/分支覆盖率评估,并基于通过率评估正确性,前提是生产代码正确。
- 使用 TsDetect 在生成的测试和 Evosuite/人工基线中检测测试异味。
- 开展两个面向研究问题的实验:RQ1(总体测试生成性能)和 RQ2(上下文要素的影响)。
- 通过对编译错误的聚类分析来分析编译根本原因,以识别常见的失败模式。
实验结果
研究问题
- RQ1RQ1:LLMs 在所选基准上为 Java MUTs 生成 JUnit 测试的能力有多强?
- RQ2RQ2:提示中不同上下文要素对 LLM 在测试生成中的表现有何影响?
- RQ3LLM 生成的测试在编译、正确性、覆盖率和异味方面与 Evosuite 有何比较?
主要发现
- Codex 在 HumanEval 上实现了超过 80% 的覆盖率,但在 SF110 上在修复前没有模型达到 2% 的覆盖率。
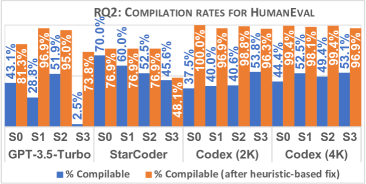
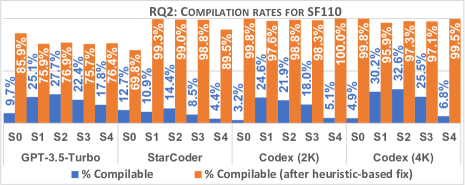
- 应用启发式修正后,跨数据集的编译率平均提升了 41%。
- StarCoder 在 SF110 上产生了最高的可编译测试比例(12.7%),但修正的改善因模型而异。
- 在 HumanEval 上,修正后 StarCoder 的测试有 70% 可编译;Codex(2K)从 37.5% 提升到 100%;Codex(4K)从 44.4% 提升到 99.4%。
- 对于 SF110,修正前的编译率普遍较低(2.7%–12.7%),修正后约提升 81%;Evosuite 的可编译性设计上达到 100%。
- 正确性率适中:StarCoder 在 HumanEval 上约 81% 正确;其他模型(Codex 变体)在 41–77% 之间;SF110 正确率较低,最佳约为 StarCoder 的 51.9%。
- HumanEval 的覆盖率:Codex(4K)达到 87.7% 的行覆盖率和 92.8% 的分支覆盖率;在某些情况下,Evosuite 和人工测试显示更高的覆盖率。
- SF110 的覆盖率显著较低(LLMs 大约 ≤2%),Evosuite 在这方面明显超过 LLM。
- 在 LLM 生成的测试中普遍存在测试异味,尤其是神奇数字(MNT)和断言轮盘赌(AR);StarCoder 在 SF110 的异味发生率尤为高(至少一个异味的情况达到 96.7%)。
- 情境场景(如是否存在 JavaDoc、实现可用性)对编译和正确性有影响;GPT-3.5-Turbo 在某些场景配置下通常表现出显著下降,而 Codex 与 StarCoder 的反应方式有所不同。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。