[論文レビュー] VGGFace2: A dataset for recognising faces across pose and age
VGGFace2を紹介する。広範な姿勢と年齢変動を含む大規模な顔データセットであり、それを用いて訓練したCNNでIJBベンチマークにおける最先端の結果を示す。
In this paper, we introduce a new large-scale face dataset named VGGFace2. The dataset contains 3.31 million images of 9131 subjects, with an average of 362.6 images for each subject. Images are downloaded from Google Image Search and have large variations in pose, age, illumination, ethnicity and profession (e.g. actors, athletes, politicians). The dataset was collected with three goals in mind: (i) to have both a large number of identities and also a large number of images for each identity; (ii) to cover a large range of pose, age and ethnicity; and (iii) to minimize the label noise. We describe how the dataset was collected, in particular the automated and manual filtering stages to ensure a high accuracy for the images of each identity. To assess face recognition performance using the new dataset, we train ResNet-50 (with and without Squeeze-and-Excitation blocks) Convolutional Neural Networks on VGGFace2, on MS- Celeb-1M, and on their union, and show that training on VGGFace2 leads to improved recognition performance over pose and age. Finally, using the models trained on these datasets, we demonstrate state-of-the-art performance on all the IARPA Janus face recognition benchmarks, e.g. IJB-A, IJB-B and IJB-C, exceeding the previous state-of-the-art by a large margin. Datasets and models are publicly available.
研究の動機と目的
- ラベルノイズを最小化しつつ、広範な姿勢・年齢・民族性・職業の変動を備えた大規模な顔データセットを作成する。
- 自動フィルタリングと手動フィルタリングの段階を備えた堅牢なデータセット構築パイプラインを説明する。
- VGGFace2で訓練されたモデルがIJBベンチマークおよび姿勢/年齢認識タスク全体で最先端の結果を達成することを示す。
提案手法
- 姿勢/年齢の変動を重視して、Google Image Searchから9131 identitiesの3.31 million imagesを収集する。
- 自動分類、ほぼ重複の除去、手動レビューを含む多段階フィルタリングを適用してラベルノイズを低減する。
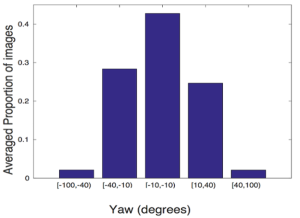
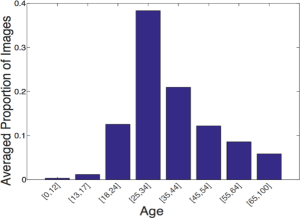
- 事前学習済み分類器を用いて姿勢(yaw/pitch/roll)と見かけ年齢を注釈付けする。
- VGGFace2、MS-Celeb-1M、およびその結合集合上でResNet-50およびSE-ResNet-50モデルを訓練し、IJB-A/B/Cベンチマークで評価する。
- クロスポーズおよびクロスエイジ認識の評価のために姿勢と年齢のテンプレートを提供する。
実験結果
リサーチクエスチョン
- RQ1固有身份内の姿勢と年齢の変動を増やすと顔認識性能にどのような影響が出るか。
- RQ2広範でノイズの多いデータセット(MS-Celeb-1M)で事前訓練し、VGGFace2で微調整することが一般化を改善するか。
- RQ3VGGFace2で訓練されたモデルは他のデータセットで訓練されたモデルと比べてIJB-A/B/Cベンチマークでどのような性能を示すか。
- RQ4姿勢と年齢の変動が異なるテンプレート(姿勢/年齢)間の認識に与える影響はどうなるか。
主な発見
- VGGFace2で訓練すると、VGGFace2テストセット上のtop-1誤差が3.9%となり、VGGFaceの10.6%およびMS1Mの5.6%を下回る。
- VGGFace2で訓練されたモデルはIJB-Aの検証および識別指標でMS1MおよびVGGFaceを上回る。
- SE-ResNet-50およびSENet系はVGGFace2で訓練され、複数のプロトコルにおいてIJB-A、IJB-B、IJB-Cベンチマークで最先端の結果を達成。
- 姿勢と年齢のテンプレートは、姿勢が類似していると認識が容易であり、年齢を跨ぐマッチングは依然として難易度が高いことを示しており、VGGFace2モデルは他よりも高い類似度スコアを提供する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。