[论文解读] ViewCo: Discovering Text-Supervised Segmentation Masks via Multi-View Semantic Consistency
ViewCo 引入文本与视图的一致性以及跨视图分割一致性,用于从图文数据学习文本监督的分割掩码,在 VOC2012、PASCAL Context 和 COCO 上实现零-shot mIoU 的最新水平。它利用多视图自监督和跨模态对比损失将多个裁剪与文本对齐。
Recently, great success has been made in learning visual representations from text supervision, facilitating the emergence of text-supervised semantic segmentation. However, existing works focus on pixel grouping and cross-modal semantic alignment, while ignoring the correspondence among multiple augmented views of the same image. To overcome such limitation, we propose multi- extbf{View} extbf{Co}nsistent learning (ViewCo) for text-supervised semantic segmentation. Specifically, we first propose text-to-views consistency modeling to learn correspondence for multiple views of the same input image. Additionally, we propose cross-view segmentation consistency modeling to address the ambiguity issue of text supervision by contrasting the segment features of Siamese visual encoders. The text-to-views consistency benefits the dense assignment of the visual features by encouraging different crops to align with the same text, while the cross-view segmentation consistency modeling provides additional self-supervision, overcoming the limitation of ambiguous text supervision for segmentation masks. Trained with large-scale image-text data, our model can directly segment objects of arbitrary categories in a zero-shot manner. Extensive experiments show that ViewCo outperforms state-of-the-art methods on average by up to 2.9\%, 1.6\%, and 2.4\% mIoU on PASCAL VOC2012, PASCAL Context, and COCO, respectively.
研究动机与目标
- 推动改进的跨模态语义对齐以提升文本监督语义分割对一对一图像文本配对的依赖
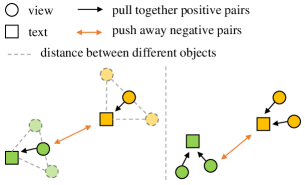
- 通过引入跨视图分割一致性作为自监督来缓解文本描述的歧义
- 利用多视图裁剪学习文本到视图的对齐,以支持密集的高层语义
- 通过在大型图像文本数据集上的预训练并迁移到标准基准来展示零-shot 分割能力
提出的方法
- 提出文本到视图的一致性建模以放宽严格的图像文本对应,并将多个图像裁剪与相同文本对齐
- 通过对比孙成对征象的交叉视图分割一致性来提供自监督
- 使用基于 GroupViT 的视觉骨干网络,并采用教师-学生 EMA 以获取跨视图分割特征并应用 NCE 基损失
- 应用多视图和多提示的图文对比损失以加强跨模态对齐并减少文本歧义的影响
- 将跨视图分割损失、文本到视图与多提示损失结合成最终训练目标
- 在 CC12M 和 CC12M+YFCC 上进行预训练,然后通过将分割标记嵌入与标签提示匹配来执行零-shot 分割

实验结果
研究问题
- RQ1放宽图像文本匹配为一对多的文本到视图范式是否能提升分割的高层跨模态语义对齐?
- RQ2跨视图分割一致性是否提供鲁棒的自监督来克服分割掩码中的文本监督歧义?
- RQ3多视图文本到视图和跨视图分割损失如何相互作用以改善在标准数据集上的零-shot 分割?
- RQ4使用 ViewCo 时 CC12M 与 CC12M+YFCC 在零-shot 语义分割方面的收益有何不同?
主要发现
| 预训练 | 模型 | 数据集 | 监督 | 零样本 | PASCAL VOC(mIoU) | PASCAL Context(mIoU) | COCO(mIoU) |
|---|---|---|---|---|---|---|---|
| CC12M | ViewCo | CC12M | 文本与自监督 | ✓ | 45.7 | 20.8 | 20.6 |
| CC12M+YFCC | ViewCo | CC12M+YFCC | 文本与自监督 | ✓ | 52.4 | 23.0 | 23.5 |
- ViewCo 在 VOC2012、PASCAL Context 和 COCO 的平均零-shot mIoU 相对于最先进基线提高最多 2.9 个百分点。
- 文本到视图一致性(一个对多)在语义对齐方面比单视图文本到图像对比具有更高的对齐效果。
- 跨视图分割一致性提供额外的自监督,提升不同视图之间的分割一致性。
- 在 CC12M 预训练下,ViewCo 在 VOC 上达到 52.4 的 mIoU,在 COCO 上达到 23.0 的 mIoU,相较于 GroupViT 有显著优势。
- 在使用 ViewCo 时零-shot ImageNet 的 Acc@1 提升,表明跨模态语义理解更强。
- ViewCo 在某些基准上接近完全监督基线的性能,显示出强大的零-shot 分割能力。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。