[论文解读] Vivim: a Video Vision Mamba for Medical Video Segmentation
Vivim 引入了 Video Vision Mamba 框架,在分层编码器中使用时空选择性状态空间建模(ST-Mamba)以高效执行医学视频对象分割。
Medical video segmentation gains increasing attention in clinical practice due to the redundant dynamic references in video frames. However, traditional convolutional neural networks have a limited receptive field and transformer-based networks are mediocre in constructing long-term dependency from the perspective of computational complexity. This bottleneck poses a significant challenge when processing longer sequences in medical video analysis tasks using available devices with limited memory. Recently, state space models (SSMs), famous by Mamba, have exhibited impressive achievements in efficient long sequence modeling, which develops deep neural networks by expanding the receptive field on many vision tasks significantly. Unfortunately, vanilla SSMs failed to simultaneously capture causal temporal cues and preserve non-casual spatial information. To this end, this paper presents a Video Vision Mamba-based framework, dubbed as Vivim, for medical video segmentation tasks. Our Vivim can effectively compress the long-term spatiotemporal representation into sequences at varying scales with our designed Temporal Mamba Block. We also introduce an improved boundary-aware affine constraint across frames to enhance the discriminative ability of Vivim on ambiguous lesions. Extensive experiments on thyroid segmentation, breast lesion segmentation in ultrasound videos, and polyp segmentation in colonoscopy videos demonstrate the effectiveness and efficiency of our Vivim, superior to existing methods. The code is available at: https://github.com/scott-yjyang/Vivim. The dataset will be released once accepted.
研究动机与目标
- 推动改进医学视频分割的长时程时序建模。
- 开发能够在多个尺度捕捉时空线索的计算高效架构。
- 在乳腺超声病变分割和结肠镜息肉分割上证明其有效性。
- 提供一个轻量级解码器,融合多级特征以预测分割掩码。
提出的方法
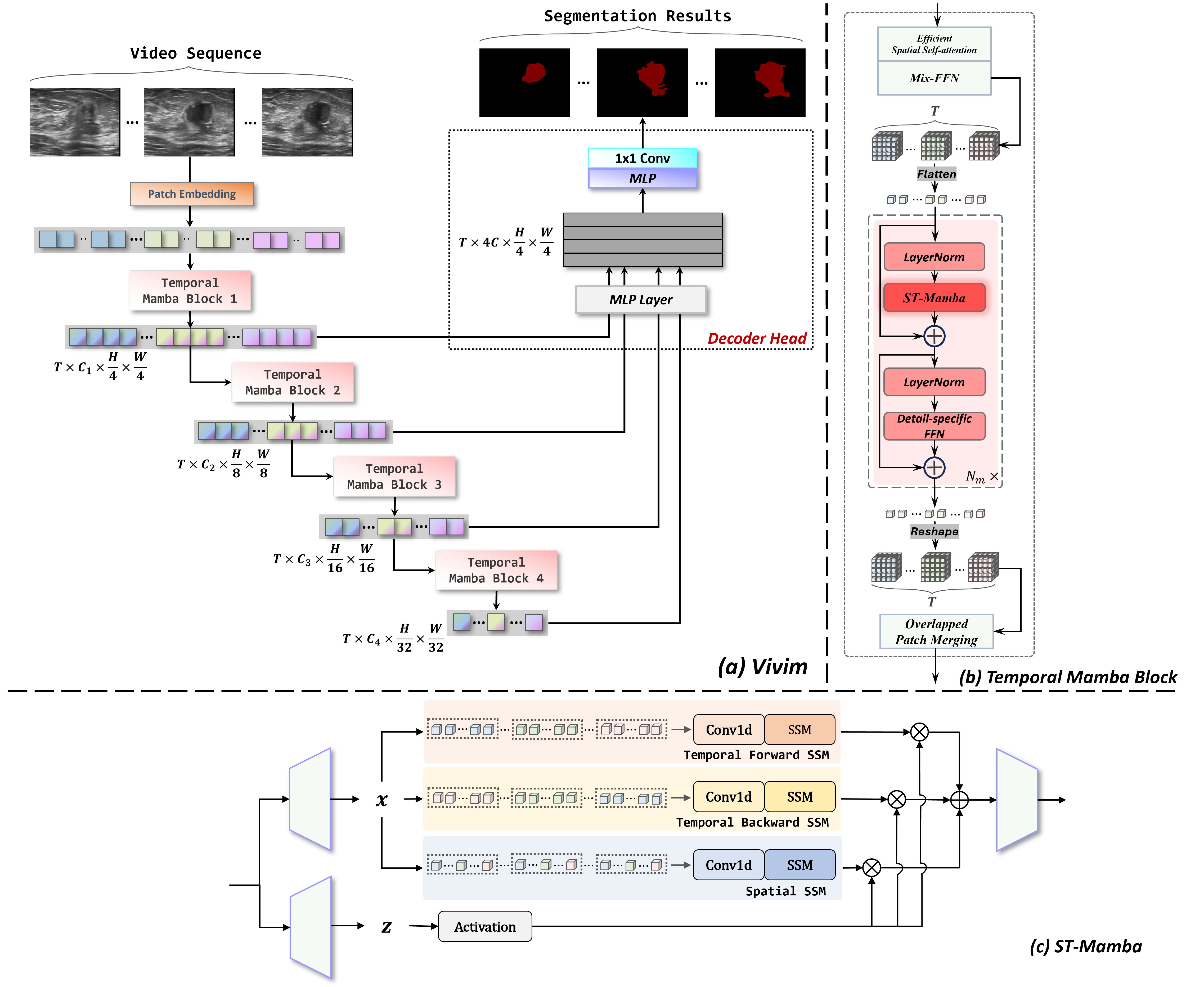
- 引入 Temporal Mamba Block,将空间注意力与时间依赖融合。
- 使用分层编码器在分辨率 1/4、1/8、1/16、1/32 下提取多级时空特征。
- 用 ST-Mamba(时空选择性掃描)替代自注意力以实现高效的长序列建模。
- 采用基于轻量级 CNN 的解码器来融合多级特征并预测分割掩码。
- 将 ST-Mamba 基于带离散 A、B、C 矩阵的状态空间模型,并采用零阶保持离散化以实现高效核构造。
- 在乳腺超声病变和结肠镜息肉视频数据集上端到端训练,使用标准损失函数(交叉熵和 IoU)。
实验结果
研究问题
- RQ1ST-Mamba 是否比传统 Transformer 自注意力在医学视频分割中更高效地捕捉长距离时空依赖?
- RQ2与单尺度方法相比,分层 Temporal Mamba 编码器是否在多尺度上提升分割性能?
- RQ3轻量级 CNN 解码器是否足以融合多级 ST-Mamba 特征以实现准确分割?
- RQ4在准确性和速度方面,Vivim 在乳腺超声病变分割和结肠镜息肉分割上的表现如何?
- RQ5对于长视频序列,ST-Mamba 与自注意力之间的计算权衡是什么?
主要发现
- Vivim 在息肉和乳腺病变视频数据集上实现强分割性能,在多项指标上超越了若干最先进的方法。
- Temporal Mamba Block 实现相对于完整自注意力在帧内和帧间依赖建模上的高效,计算成本降低。
- ST-Mamba 通过时空选择性扫描,能够有效处理长视频序列,同时保持比许多基于 Transformer 的方法更高的 FPS。
- 分层编码器提供多尺度表示,提升医学视频中的边界精度和分割保真度。
- 在 CVC-300、CVC-612、ASU-Mayo 以及乳腺 US 数据集上的实验证明了 Vivim 的通用性和有效性。
- Vivim 在乳腺超声数据集上实现更优的运行时性能,显示出速度与准确性的双重优势。

更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。