[论文解读] Voice Transformer Network: Sequence-to-Sequence Voice Conversion Using Transformer with Text-to-Speech Pretraining
论文提出了一个 Voice Transformer Network (VTN),它使用基于 Transformer 的 seq2seq 语音转换模型,并采用两阶段 Text-to-Speech 预训练策略,以提高数据效率和语音质量,且优于基于 RNN 的基线。
We introduce a novel sequence-to-sequence (seq2seq) voice conversion (VC) model based on the Transformer architecture with text-to-speech (TTS) pretraining. Seq2seq VC models are attractive owing to their ability to convert prosody. While seq2seq models based on recurrent neural networks (RNNs) and convolutional neural networks (CNNs) have been successfully applied to VC, the use of the Transformer network, which has shown promising results in various speech processing tasks, has not yet been investigated. Nonetheless, their data-hungry property and the mispronunciation of converted speech make seq2seq models far from practical. To this end, we propose a simple yet effective pretraining technique to transfer knowledge from learned TTS models, which benefit from large-scale, easily accessible TTS corpora. VC models initialized with such pretrained model parameters are able to generate effective hidden representations for high-fidelity, highly intelligible converted speech. Experimental results show that such a pretraining scheme can facilitate data-efficient training and outperform an RNN-based seq2seq VC model in terms of intelligibility, naturalness, and similarity.
研究动机与目标
- 激励使用 seq2seq 语音转换 (VC) 来捕捉韵律和时长的变化。
- 利用 Transformer 架构用于 VC ,以取代基于 RNN/CNN 的模型。
- 引入基于 TTS 的两阶段预训练,以提高数据效率并减少发音错误。
- 证明基于 TTS 预训练的 VC 即使在有限的 VC 数据下也能产生高质量、清晰的语音。
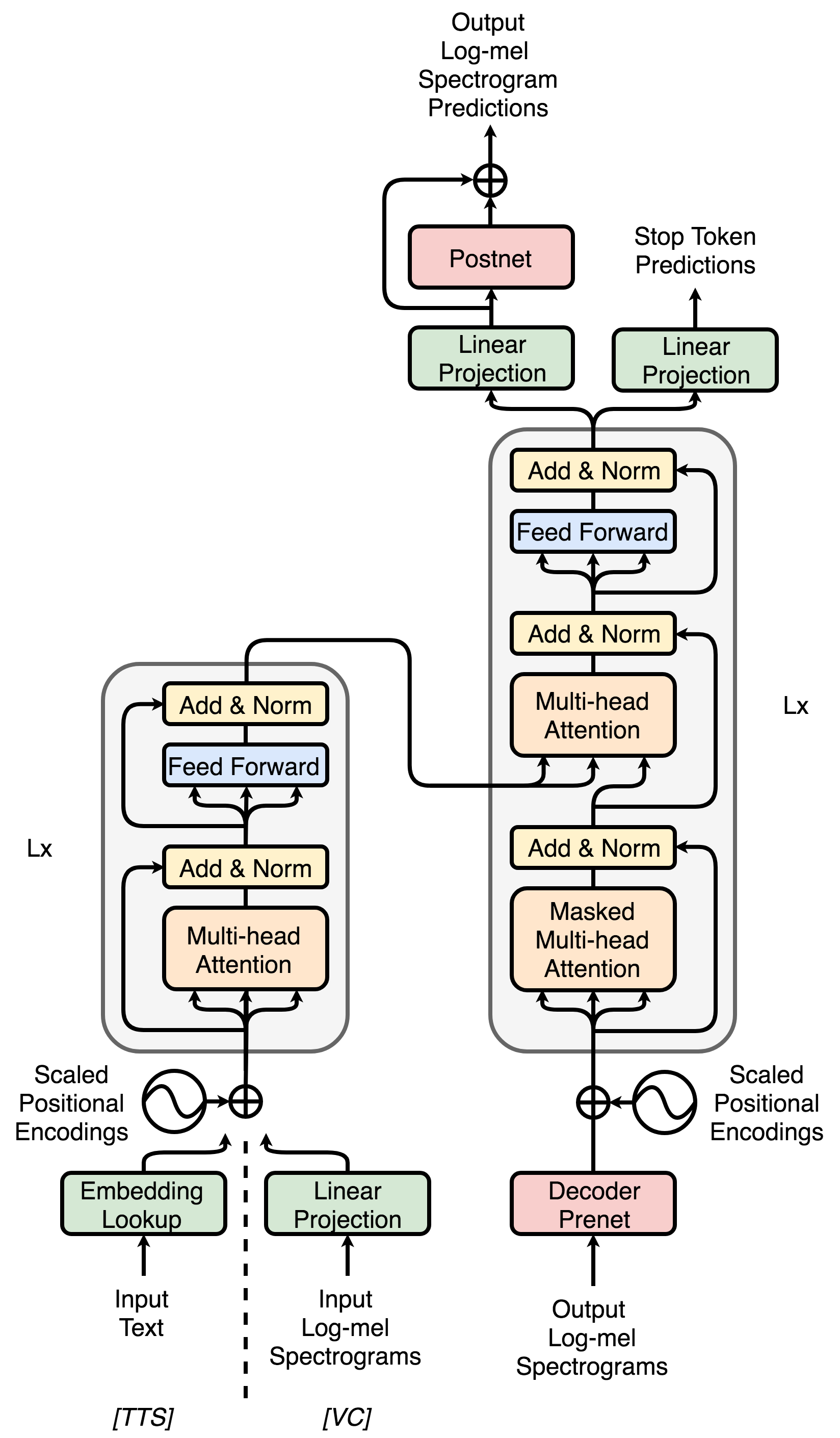
提出的方法
- 通过用线性投影替代编码器输入嵌入,将 Transformer-TTS 架构调整用于 VC。
- 引入编码器缩减因子以堆叠帧并在训练期间稳定注意力。
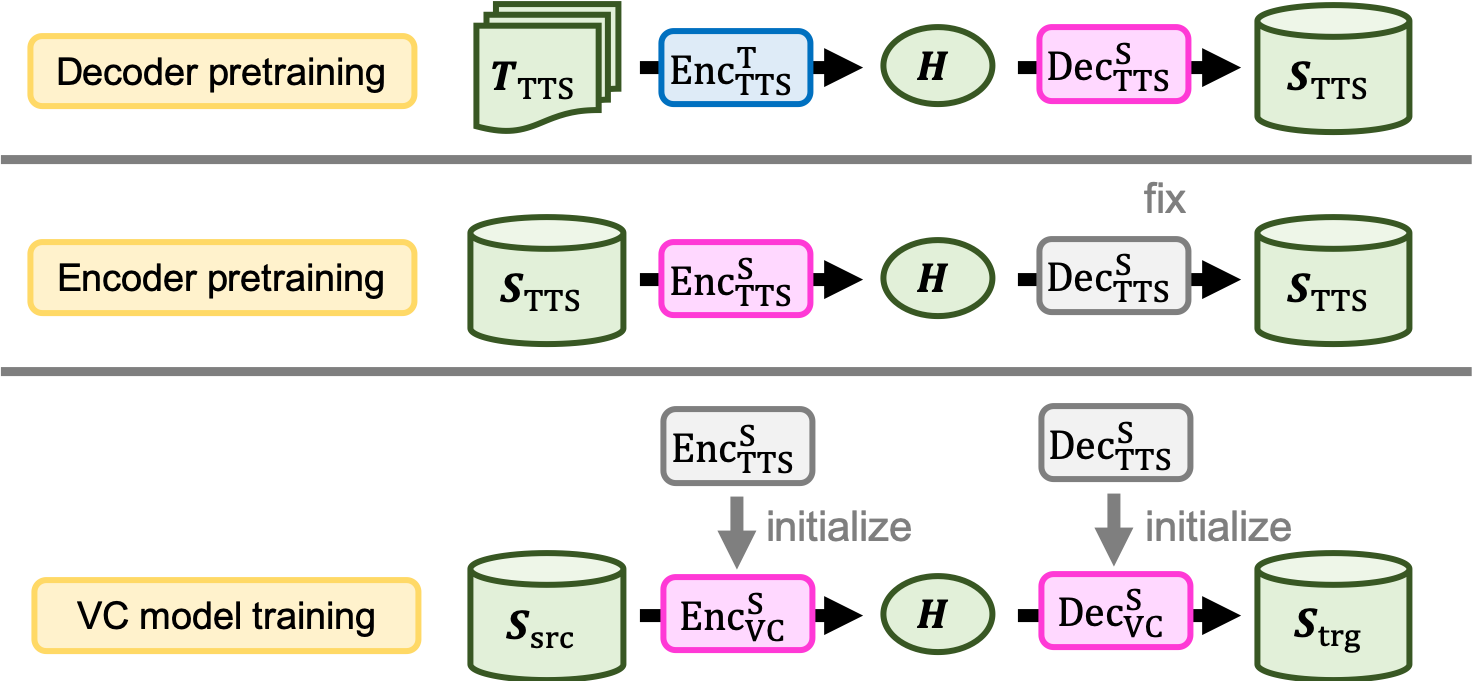
- 提出两阶段预训练:解码器在大规模 TTS 数据上进行预训练;编码器通过自编码器在固定的预训练解码器下进行预训练。
- 使用多说话人、非并行的 TTS 和 VC 数据,进行两阶段训练,以将细粒度表示从 TTS 转移到 VC。
- 使用 MCD、CER、WER 以及 MOS 风格的主观测试来评估光谱保真度和可懂度。
实验结果
研究问题
- RQ1基于 Transformer 的 seq2seq VC 模型是否能在可懂度和自然度方面优于基于 RNN 的 seq2seq VC 模型?
- RQ2用大规模 TTS 数据对 VC 组件进行预训练是否能提高小型 VC 数据集上的数据效率和鲁棒性?
- RQ3所提 VC 系统在光谱畸变、ASR 兼容性,以及感知自然度和相似性方面的表现如何?
主要发现
- 在相同数据条件下,使用 TTS 预训练的 VTN 在客观指标上持续优于基线 ATTS2S。
- 将编码器预训练与解码器预训练结合可带来稳健增益,特别是在 VC 数据量减少时。
- 在全量训练数据下,VTN 在主观测试中的自然度和相似性显著优于基线。
- 即使 VC 数据非常有限(例如 80 个说话,总),VTN 仍然优于基线,表明强数据效率。
- 与仅 TTS 适配相比,带预训练的 VTN 能实现更高的自然度和相似性,因为更好地保留了韵律和语言表示。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。