[论文解读] A Comparative Study of Quality Evaluation Methods for Text Summarization
该论文比较了用于专利文档摘要的八种自动评估指标与人工评估,并引入一个基于LLM的评估框架,与人工判断高度一致,优于 ROUGE、BERTScore 和 SummaC 等传统指标。
Evaluating text summarization has been a challenging task in natural language processing (NLP). Automatic metrics which heavily rely on reference summaries are not suitable in many situations, while human evaluation is time-consuming and labor-intensive. To bridge this gap, this paper proposes a novel method based on large language models (LLMs) for evaluating text summarization. We also conducts a comparative study on eight automatic metrics, human evaluation, and our proposed LLM-based method. Seven different types of state-of-the-art (SOTA) summarization models were evaluated. We perform extensive experiments and analysis on datasets with patent documents. Our results show that LLMs evaluation aligns closely with human evaluation, while widely-used automatic metrics such as ROUGE-2, BERTScore, and SummaC do not and also lack consistency. Based on the empirical comparison, we propose a LLM-powered framework for automatically evaluating and improving text summarization, which is beneficial and could attract wide attention among the community.
研究动机与目标
- 评估现有自动摘要评估指标在长文本专利中的有效性。
- 评估人类评估在判断摘要质量方面与自动指标的对比。
- 探讨大语言模型(LLMs)作为摘要自动评估者的可行性。
- 提出一个基于LLM的框架,用于自动评估并迭代改进摘要。
提出的方法
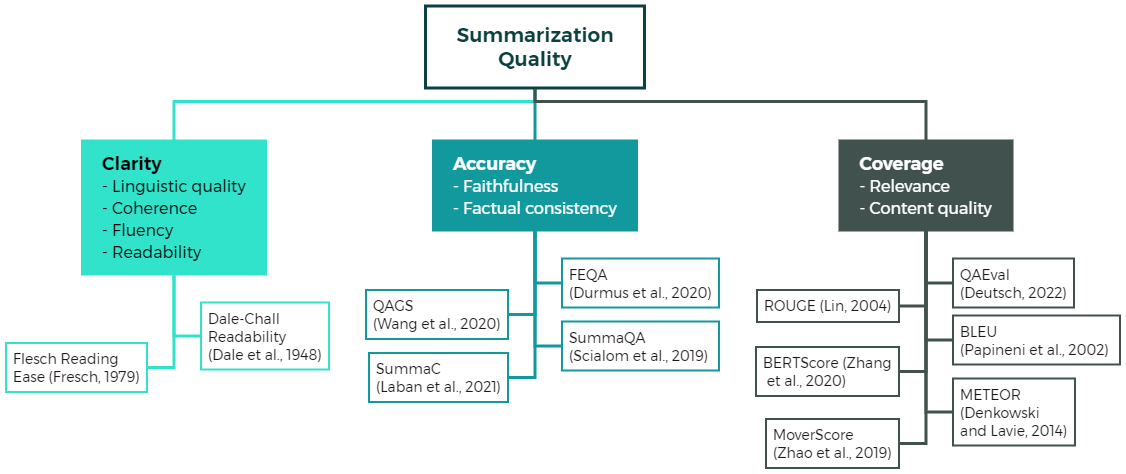
- 在专利语料库上评估SOTA摘要模型(T5、XLNet、BART、BigBird、Pegasus、GPT-3.5、LongT5、Llama-3),使用八种自动评估指标和人工评估。
- 在长篇专利文本上重新评估广泛使用的自动评估指标(ROUGE-1/2/L、BLEU、BERTScore、SummaC、FRE、DCR)。
- 在四个质量维度(清晰度、准确性、覆盖范围、总体质量)上进行人工评估,评审员具备领域知识。
- 实现基于LLM的评估方法,使用与人工指示完全相同的提示来评估摘要质量。
- 进行元分析(Kendall Tau-b、Spearman、Pearson)比较自动指标、人工评估和基于LLM的评估。
- 展示一个迭代改进循环,其中LLM反馈用于后续摘要生成。
实验结果
研究问题
- RQ1当前的自动评估指标与长篇专利摘要的人类判断之间的相关性有多强?
- RQ2基于LLM的评估能否复制或超越人类评估在判断摘要质量方面的能力?
- RQ3以LLM引导的迭代改进循环是否在关键维度上提升摘要质量?
主要发现
- ROUGE-2、BERTScore 和 SummaC 在专利摘要上的与人工评估相关性非常弱或不显著。
- 可读性指标(FRE、DCR)与大多数指标及人类判断呈负相关。
- LLMs(包括开源的 Llama-3-8B 和 GPT-4)在准确性、覆盖率和总体质量等方面与人工评估高度一致(高 Kendall/Spearman 相关性)。
- GPT-3.5-turbo-16k 在人类和LLM评估中产生了最佳的总体摘要质量。
- 将LLM口头反馈融入提示用于迭代改进,显著提升清晰度和覆盖率,但准确性略有下降。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。