[论文解读] A Comprehensive Survey on Data Augmentation
本文提出一种与模态无关、以数据为中心的数据增强与综述技术分类法,覆盖五种数据模态(图像、文本、图、表格、时间序列)。
Data augmentation is a series of techniques that generate high-quality artificial data by manipulating existing data samples. By leveraging data augmentation techniques, AI models can achieve significantly improved applicability in tasks involving scarce or imbalanced datasets, thereby substantially enhancing AI models' generalization capabilities. Existing literature surveys only focus on a certain type of specific modality data and categorize these methods from modality-specific and operation-centric perspectives, which lacks a consistent summary of data augmentation methods across multiple modalities and limits the comprehension of how existing data samples serve the data augmentation process. To bridge this gap, this survey proposes a more enlightening taxonomy that encompasses data augmentation techniques for different common data modalities by investigating how to take advantage of the intrinsic relationship between and within instances. Additionally, it categorizes data augmentation methods across five data modalities through a unified inductive approach.
研究动机与目标
- 阐明需要通过数据增强来应对数据稀缺或不平衡并改善泛化能力。
- 提出一种模态无关、以数据为中心的数据增强分类法。
- 使用统一的归纳方法,对五种数据模态的增强技术进行分类。
- 分析如何利用每种模态内的信息来进行增强。
- 提供最新的数据增强方法及其理论基础的综合综述。
提出的方法
- 将数据增强形式化为一个将带标签的数据集转换为增强数据集的函数 f_theta。
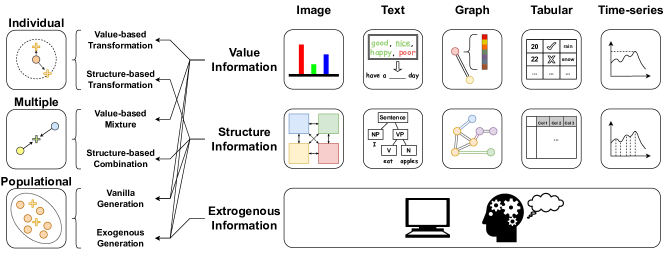
- 基于信息来源引入两层分类法: Individual、Multiple 和 Populational Augmentation。
- 进一步分类为:(i) 使用信息的哪一部分(基于数值信息 vs 基于结构的信息),以及 (ii) 用于生成新数据的样本数量(样本级、成对、总体)。
- 在总体增强中区分 Vanilla(数值/结构)与 Exogenous 生成。
- 将该分类法应用于五种模态,并对每种模态的代表性技术进行评审。
- 总结跨模态的核心趋势与最新文献。
实验结果
研究问题
- RQ1RQ1:用于生成每个新样本的样本数量(individual、multiple、populational)。
- RQ2RQ2:用于生成新数据的信息的哪一部分(基于数值 vs 基于结构)。
- RQ3RQ3:模态无关的分类法如何揭示不同数据类型之间的共性模式。
- RQ4RQ4:最新的图像、文本、图、表格数据和时间序列的数据增强方法如何适配到所提出的分类法。
主要发现
- 本文提供一种适用于所有五种数据模态的模态无关、以数据为中心的分类法。
- 它确认了三种增强类型(individual、multiple、populational)和两种信息来源(value vs structure)用于分类。
- 它整合并对图像、文本、图、表格数据和时间序列模态的最新数据增强文献进行分类。
- 它强调通过统一原则,利用每种模态内的信息来进行增强。
- 它在所提出的框架内对当前技术进行调查与综合,包括自动策略搜索和基于 mixup 的策略。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。