[论文解读] A Context-Aware Citation Recommendation Model with BERT and Graph Convolutional Networks
该论文提出了一种上下文感知的引用推荐模型,采用 BERT 进行上下文文本编码,并利用图卷积网络(GCN)建模引用关系,在平均平均精度(MAP)和召回率@k 上实现了 28% 的性能提升,达到当前最先进水平。该研究还提出了 FullTextPeerRead 数据集,这是首个将上下文句子与论文元数据相结合的结构化基准数据集,用于引用推荐任务。
With the tremendous growth in the number of scientific papers being published, searching for references while writing a scientific paper is a time-consuming process. A technique that could add a reference citation at the appropriate place in a sentence will be beneficial. In this perspective, context-aware citation recommendation has been researched upon for around two decades. Many researchers have utilized the text data called the context sentence, which surrounds the citation tag, and the metadata of the target paper to find the appropriate cited research. However, the lack of well-organized benchmarking datasets and no model that can attain high performance has made the research difficult. In this paper, we propose a deep learning based model and well-organized dataset for context-aware paper citation recommendation. Our model comprises a document encoder and a context encoder, which uses Graph Convolutional Networks (GCN) layer and Bidirectional Encoder Representations from Transformers (BERT), which is a pre-trained model of textual data. By modifying the related PeerRead dataset, we propose a new dataset called FullTextPeerRead containing context sentences to cited references and paper metadata. To the best of our knowledge, This dataset is the first well-organized dataset for context-aware paper recommendation. The results indicate that the proposed model with the proposed datasets can attain state-of-the-art performance and achieve a more than 28% improvement in mean average precision (MAP) and recall@k.
研究动机与目标
- 为解决上下文感知引用推荐缺乏标准化基准数据集的问题,该问题阻碍了可复现的研究与模型评估。
- 通过结合 BERT 的上下文文本理解能力与 GCN 的引用网络结构建模能力,提升引用推荐性能。
- 构建一个可复现、结构清晰的数据集——FullTextPeerRead,包含上下文句子、参考文献元数据以及来自学术论文的引用链接。
- 探究上下文长度与引用频率对引用推荐任务中模型性能的影响。
- 提供一种新的最先进模型,在 MAP、MRR 和召回率@k 指标上均优于现有方法。
提出的方法
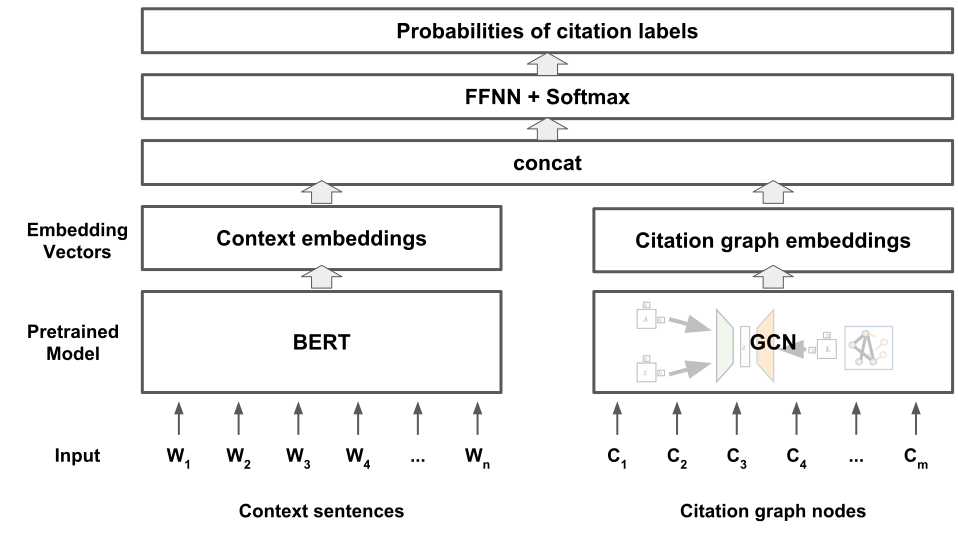
- 该模型采用双编码器架构:基于 BERT 的上下文编码器,用于编码引用占位符周围的上下文文本。
- 图卷积网络(GCN)层处理引用网络数据,从论文引用图中学习潜在表示。
- 应用变分图自编码器(VGAE)对 GCN 编码器进行正则化,以减少对局部上下文模式的过拟合。
- 最终表示通过结合 BERT 的上下文嵌入与 GCN 的图嵌入,计算候选引用的相似度得分。
- FullTextPeerRead 数据集通过 arXiv Vanity 解析基于 LaTeX 的 PDF 文件构建,提取上下文句子与元数据,并将上下文感知的引用信息增强至 PeerRead 和 AAN 数据集。
- 模型通过对比学习进行端到端训练,以优化将相关引用排在推荐列表更靠前位置的目标。
实验结果
研究问题
- RQ1与仅使用 BERT 相比,BERT 与 GCN 的联合使用在多大程度上提升了引用推荐性能?
- RQ2上下文序列长度在多大程度上影响模型在引用推荐任务中的性能表现?
- RQ3目标论文的引用频率在多大程度上影响模型准确推荐它们的能力?
- RQ4像 FullTextPeerRead 这样统一且结构清晰的数据集,是否能够实现引用推荐研究中的一致性基准测试与可复现性?
- RQ5通过 GCN 建模图结构的引用关系,在仅依赖文本上下文的基础上,对相关性估计的提升作用有多大?
主要发现
- 所提出的 BERT-GCN 模型在平均平均精度(MAP)和召回率@k 上相比基线模型实现了 28% 的性能提升。
- 引入 GCN 的模型优于仅使用 BERT 的模型,在引用频率为 5 时,MAP 达到 0.6736,而仅使用 BERT 的模型为 0.6593。
- 当上下文长度超过 100 个 token 后,性能增益趋于平缓,表明超过某一上下文窗口后收益递减。
- 目标论文的引用频率越高,模型性能越佳,表明频繁引用为训练提供了更可靠的信号。
- FullTextPeerRead 数据集能够实现准确且一致的上下文抽取,其元数据与上下文句子结构清晰,来源于真实的学术论文。
- GCN 通过捕捉引用网络结构提升了性能,使相似度估计超越仅依赖文本嵌入的水平。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。