[论文解读] A Practical Mixed Precision Algorithm for Post-Training Quantization
本文提出一种后训练混合精度量化方法:通过 SQNR 构建逐层敏感性列表,然后使用 Pareto 前沿贪心搜索在硬件和精度预算下分配比特宽度,并结合 AdaRound 提升低比特性能,且无需训练数据。
Neural network quantization is frequently used to optimize model size, latency and power consumption for on-device deployment of neural networks. In many cases, a target bit-width is set for an entire network, meaning every layer get quantized to the same number of bits. However, for many networks some layers are significantly more robust to quantization noise than others, leaving an important axis of improvement unused. As many hardware solutions provide multiple different bit-width settings, mixed-precision quantization has emerged as a promising solution to find a better performance-efficiency trade-off than homogeneous quantization. However, most existing mixed precision algorithms are rather difficult to use for practitioners as they require access to the training data, have many hyper-parameters to tune or even depend on end-to-end retraining of the entire model. In this work, we present a simple post-training mixed precision algorithm that only requires a small unlabeled calibration dataset to automatically select suitable bit-widths for each layer for desirable on-device performance. Our algorithm requires no hyper-parameter tuning, is robust to data variation and takes into account practical hardware deployment constraints making it a great candidate for practical use. We experimentally validate our proposed method on several computer vision tasks, natural language processing tasks and many different networks, and show that we can find mixed precision networks that provide a better trade-off between accuracy and efficiency than their homogeneous bit-width equivalents.
研究动机与目标
- 通过利用逐层对量化的鲁棒性而非统一比特宽度来提升设备端性能的动机。
- 开发一种需要极少数据且无需超参数调优的后训练量化方法。
- 通过量化器分组和效率度量来引入实际硬件约束。
- 展示对校准数据变化和域外输入的鲁棒性。
- 证明所提出的方法在多种模型上比同质量化具有更好的精度-效率权衡。
提出的方法
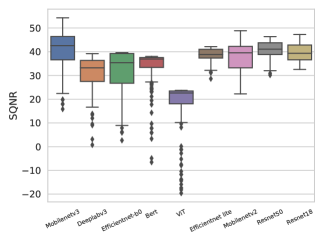
- 阶段1 通过对每一层在不同量化选项下测量网络损失来创建逐层敏感性清单,使用 SQNR 作为敏感性度量。
- 阶段2 从最高精度量化开始,利用敏感性清单在 Pareto 前沿贪心搜索的引导下迭代降低比特宽度,以达到预定义的性能预算。
- 引入量化器分组以强制硬件约束,使组内共享操作使用一致的精度。
- 整合 AdaRound 以通过在阶段1的敏感性测量中使用 AdaRounded 权重、随后在不同比特宽度配置之间拼接这些权重,提升低比特量化性能。
- 可通过二分搜索加插值策略来加速搜索,以利用单调的 Pareto 曲线并降低运行时。
- 该方法在阶段1中不需要标签,在有限校准数据下也能容忍数据变化且具有鲁棒性。
实验结果
研究问题
- RQ1后训练混合精度量化能否在 CV 和 NLP 任务中优于固定精度量化的若干架构?
- RQ2对校准数据变动和使用域外数据进行敏感性估计的鲁棒性如何?
- RQ3硬件约束(如量化器分组)如何影响可行的混合精度配置及性能?
- RQ4将 AdaRound 与混合精度流程结合是否在很低比特宽度下提升准确性?
主要发现
- 所提出的 PTQ MP 方法在 Mobilenetv3、Deeplabv3、Efficientnet、BERT、ViT 等多种模型上,找到的混合精度配置在准确性-效率权衡上优于同质比特宽度网络。
- 基于 SQNR 的逐层敏感性清单对校准数据变动和校准图像数量表现出鲁棒性,相对于基于准确性的敏感性具有有利的 Kendall Tau 相关性。
- 将 AdaRound 集成到混合精度流水线中,在低比特(小于 8)量化性能上有提升,甚至可超越固定精度的 AdaRound。
- 通过二分搜索和插值策略改进阶段2的运行时间,在保持良好 Pareto 曲线的同时降低了搜索复杂度。
- 方法在多种比特宽度候选集合(如 W4A8、W8A8、W8A16)以及扩展的低比特空间(如 W4A4、W6A6 等)下仍然有效。
- 阶段1和阶段2 可以在几乎不需要任务数据的情况下运行,适用于域外或隐私保护的校准场景。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。