[论文解读] A Reality check of the benefits of LLM in business
本论文通过对四个可访问的LLM在真实世界数据上的测试,实证评估大型语言模型(LLMs)在核心业务流程中的有用性与就绪程度,强调偏见、上下文理解和提示敏感性方面的局限性。
Large language models (LLMs) have achieved remarkable performance in language understanding and generation tasks by leveraging vast amounts of online texts. Unlike conventional models, LLMs can adapt to new domains through prompt engineering without the need for retraining, making them suitable for various business functions, such as strategic planning, project implementation, and data-driven decision-making. However, their limitations in terms of bias, contextual understanding, and sensitivity to prompts raise concerns about their readiness for real-world applications. This paper thoroughly examines the usefulness and readiness of LLMs for business processes. The limitations and capacities of LLMs are evaluated through experiments conducted on four accessible LLMs using real-world data. The findings have significant implications for organizations seeking to leverage generative AI and provide valuable insights into future research directions. To the best of our knowledge, this represents the first quantified study of LLMs applied to core business operations and challenges.
研究动机与目标
- 评估 LLMs 在商业流程中的有用性和就绪度。
- 评估 LLMs 的局限性,如偏见、上下文理解和提示敏感性。
- 在多个可访问的 LLMs 上使用真实数据进行实验以量化能力。
- 为组织提供见解并指明未来研究方向。
提出的方法
- 对常见 LLMs 及其在商业中的用例进行调查与讨论。
- 使用来自四个可访问 LLMs 的真实数据进行实验,以测试有用性和能力。
- 通过测试 LLMs 为项目规划提出参考文献的能力来进行偏见分析。
- 从自然语言问题生成 SQL 查询的代码生成实验。
- 情境化提示实验以展示提供相关上下文的重要性。
- 使用 Poe 作为包装器来访问多个基于网络的 LLMs 并自动化收集回应。
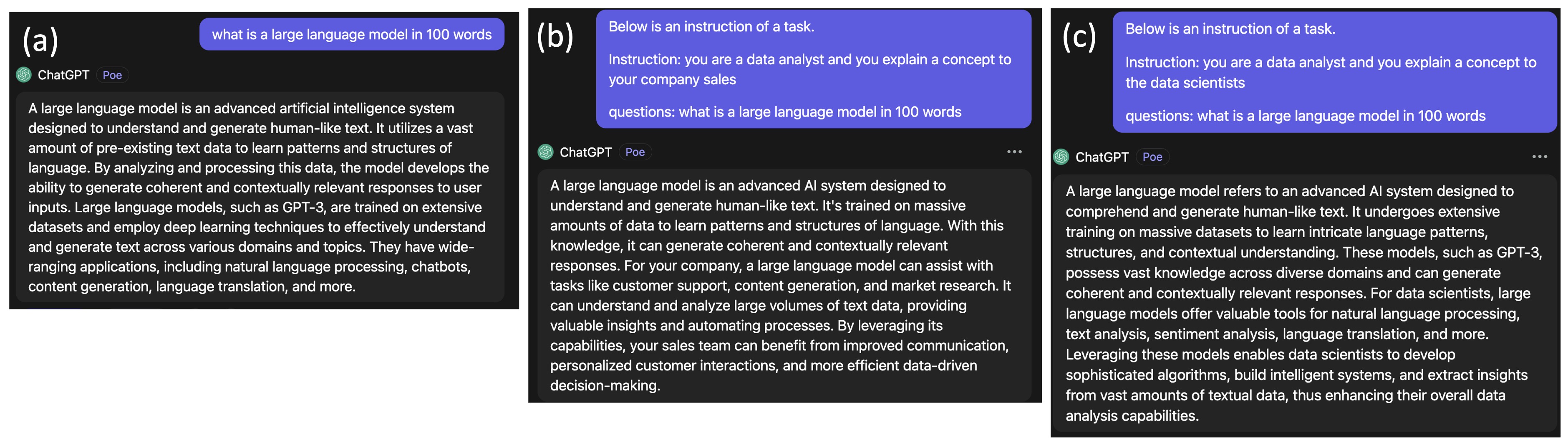
实验结果
研究问题
- RQ1在商业情境下,LLMs 在规划、实施、服务和决策制定中的有用性如何?
- RQ2在商业应用中,LLMs 的主要局限性是什么(偏见、上下文理解、提示敏感性)?
- RQ3LLMs 在文献综述的参考文献生成和基于商业问题的 SQL 代码生成等任务中的表现如何?
- RQ4上下文和提示设计在多大程度上影响 LLM 在商业任务中的输出?
主要发现
- 在偏见相关实验中,Claude-instant 在参考文献生成准确性方面获得了最高的平均匹配(约 1.9/50)。
- ChatGPT 的平均匹配参考文献约为 1.73,落后于 Claude-instant。
- LLMs 在单表 SQL 查询上的表现优于需要多表上下文的联接查询。
- 提示敏感性对输出影响显著,强调在提示中提供适当上下文的必要性。
- LLMs 在编码和多表数据分析等任务中对复杂推理和上下文的处理存在困难,表明在某些商业应用中的就绪程度有限。

更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。