[论文解读] A Survey on Mamba Architecture for Vision Applications
本综述评估 Vision Mamba (ViM) 与 VideoMamba, detailing 双向/时空扫描结合状态空间模型以实现近线性可扩展性的视觉任务,并在图像、视频与三维任务中比较它们的性能。
Transformers have become foundational for visual tasks such as object detection, semantic segmentation, and video understanding, but their quadratic complexity in attention mechanisms presents scalability challenges. To address these limitations, the Mamba architecture utilizes state-space models (SSMs) for linear scalability, efficient processing, and improved contextual awareness. This paper investigates Mamba architecture for visual domain applications and its recent advancements, including Vision Mamba (ViM) and VideoMamba, which introduce bidirectional scanning, selective scanning mechanisms, and spatiotemporal processing to enhance image and video understanding. Architectural innovations like position embeddings, cross-scan modules, and hierarchical designs further optimize the Mamba framework for global and local feature extraction. These advancements position Mamba as a promising architecture in computer vision research and applications.
研究动机与目标
- 评估 Mamba 架构如何将状态空间模型应用于可视化数据。
- 讨论 ViM 与 VideoMamba 的设计选择,以处理空间与时间依赖性。
- 评估架构创新(位置嵌入、跨扫描模块、分层设计)及其对性能的影响。
- 为在图像、视频和多任务视觉应用中选择基于 Mamba 的架构提供对比性指导。
提出的方法
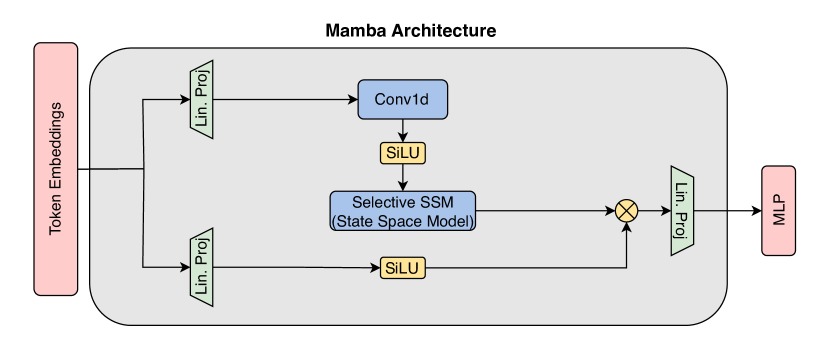
- 描述 Mamba 块和选择性扫描(S6)机制。
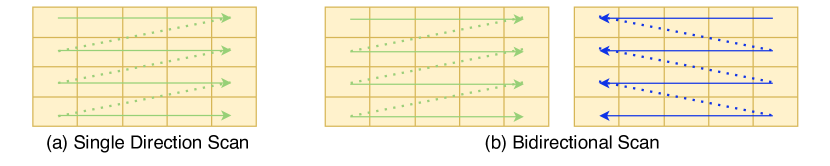
- 解释 Vision Mamba (ViM) 的双向扫描与位置嵌入。
- 解释 VideoMamba 的三维双向扫描与时空处理。
- 总结架构变体(跨扫描模块、LocalMamba、Spatial-Mamba、VSSD、Hi-Mamba、Famba-V 等)及其用途。
- 在标准视觉基准与任务上对 ViM 与 VideoMamba 进行对比。
实验结果
研究问题
- RQ1ViM/VideoMamba 的双向与时空扫描相较于 Transformer,对图像与视频任务的性能有何影响?
- RQ2哪些架构创新(如位置嵌入、SASF、寄存令牌、屏蔽的向后计算等)在不同任务上体现出最佳的准确性-效率权衡?
- RQ3在 Imagenet-1k、ADE20K、MS-COCO、Kinetics-400、SSv2 上,ViM/VideoMamba 变体在复杂度(参数量、FLOPS)与精度之间的权衡如何?
- RQ4在视觉与视频领域实现与基于 Transformer 的模型并驾平衡还存在哪些挑战?
- RQ5未来方向如何扩展 Mamba 在二维/三维视觉与多模态融合中的适用性?
主要发现
- ViM 变体在图像分类方面表现突出,Vmamba-S 在 ImageNet-1k 上达到 83.6% 的 Top-1 准确率,Spatial-Mamba-S 达到 84.6%。
- Vmamba-S 与 Spatial-Mamba-S 在 ADE20K 上也提供领先的语义分割性能(Vmamba-S 的 mIoU 约为 50.6)。
- 在 MS-COCO 的目标检测中,Spatial Mamba-S 达到 54.2 的 bbox@75 AP,VSSD-S 达到 53.1 的 bbox@75 AP,显示出具有结构感知或非因果机制的强大性能。
- VideoMamba 变体在长程视频理解方面表现卓越,VideoMamba-S 在 Kinetics-400 上达到 81.5% 的 Top-1,VideoMambaPro-S 达到 88.5%。
- EfficientViM-M4 展示了极佳的准确性-效率平衡(81.9% Top-1,参数量 21.3M,4.1 GFLOPS)用于图像分类。
- VideoMambaPro-S 通过残差/屏蔽向后策略较 VideoMamba-S 提升,在相似或更低的 FLOPS 下获得更高的准确性。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。