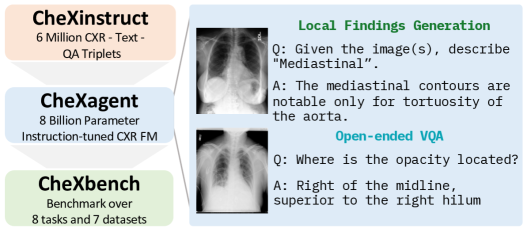
[论文解读] A Vision-Language Foundation Model to Enhance Efficiency of Chest X-ray Interpretation
论文介绍 CheXinstruct、CheXagent、CheXbench,构建并评估用于胸部X线解读的视觉-语言基础模型,在基线之上取得显著提升并评估公平性。
Over 1.4 billion chest X-rays (CXRs) are performed annually due to their cost-effectiveness as an initial diagnostic test. This scale of radiological studies provides a significant opportunity to streamline CXR interpretation and documentation. While foundation models are a promising solution, the lack of publicly available large-scale datasets and benchmarks inhibits their iterative development and real-world evaluation. To overcome these challenges, we constructed a large-scale dataset (CheXinstruct), which we utilized to train a vision-language foundation model (CheXagent). We systematically demonstrated competitive performance across eight distinct task types on our novel evaluation benchmark (CheXbench). Beyond technical validation, we assessed the real-world utility of CheXagent in directly drafting radiology reports. Our clinical assessment with eight radiologists revealed a 36% time saving for residents using CheXagent-drafted reports, while attending radiologists showed no significant time difference editing resident-drafted or CheXagent-drafted reports. The CheXagent-drafted reports improved the writing efficiency of both radiology residents and attending radiologists in 81% and 61% of cases, respectively, without loss of quality. Overall, we demonstrate that CheXagent can effectively perform a variety of CXR interpretation tasks and holds potential to assist radiologists in routine clinical workflows.
研究动机与目标
- 为胸部X线创建覆盖多任务的大规模指令调优数据集(CheXinstruct)
- 开发一个8B参数的胸部X线解读视觉-语言基础模型(CheXagent)
- 通过包含临床LLM、CXR视觉编码器和桥接模块的训练流程,将视觉和语言连接起来。
- 建立 CheXbench,以评估胸部X线视觉-语言基础模型在图像感知和文本理解方面的性能。
- 评估模型在性别、种族和年龄上的公平性,以提高透明度。
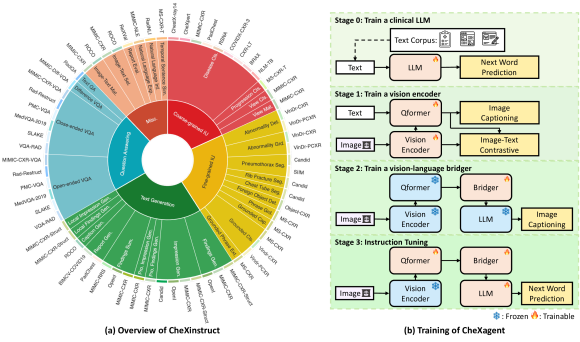
提出的方法
- 将 CheXinstruct 由 34 个任务和 65 个数据集整合为用于胸部X线的 6.1M 条指令-回答三元组。
- 构建 CheXagent,配备视觉编码器、视觉-语言桥接器和语言解码器;通过四个阶段训练,包括将大语言模型适配到临床文本。
- 阶段0:使用 PMC 摘要、MIMIC-IV 放射科报告、出院小结、维基百科术语和 CheXinstruct 数据来训练临床LLM。
- 阶段1:在 MIMIC-CXR、PadChest 和 BIMCV-COVID-19 数据集上,使用 ITC 和 IC 目标训练 CXR 视觉编码器。
- 阶段2:在冻结LLM和视觉编码器的情况下训练视觉-语言桥接器,以对齐影像-文本表示。
- 阶段3:在 CheXinstruct 任务上对多模态模型进行指令微调,采用以回答为焦点的下一个词预测目标。
实验结果
研究问题
- RQ1大规模指令调优数据集是否能使多模态基础模型实现对胸部X线的鲁棒解读?
- RQ2在核心感知和文本生成任务上,与通用域和医学领域的FM相比,基于CXRs预训练的视觉-语言FM的表现如何?
- RQ3此类模型在性别、种族和年龄维度上的公平性含义与潜在偏见是什么?
- RQ4所提出的 CheXbench 是否为多模态胸部X线解读任务提供了可靠的基准评测框架?
- RQ5在发现生成与摘要任务中,对于放射科医生级别的质量可以达到到什么程度?
主要发现
- CheXagent 在 CheXbench 轴1的图像感知任务上平均超越通用域FM 97.5%。
- CheXagent 在轴1的图像感知任务上平均超越医学领域FM 55.7%。
- 在视图分类任务上,CheXagent 在 MIMIC-CXR 和 CheXpert 数据集上相对于基线取得了巨大的性能提升(几乎完美)。
- 在视觉问答任务上,CheXagent 取得强劲结果并能泛化到留出数据集(SLAKE、Rad-Restruct)。
- 在文本生成任务中,CheXagent 在私有和 MIMIC-CXR 数据集上表现出色的发现生成,并在与更大LLM相比的摘要性能方面具有竞争力。
- 放射科医生的评阅研究表明,CheXagent 在发现摘要方面与医生相当,并指出发现生成中的差距,并给出改进的定性见解。
- 公平性分析显示在性别、种族和年龄上存在性能差异,强调需要多样化数据和偏见缓解。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。