[论文解读] Accelerating Large Language Model Decoding with Speculative Sampling
推测性采样通过使用快速草拟模型一次草拟多个令牌,然后采用改良的拒绝采样方案以保持目标模型的分布,在不修改目标模型的前提下,使 Chinchilla 70B 的解码速度提升约 2–2.5 倍。
We present speculative sampling, an algorithm for accelerating transformer decoding by enabling the generation of multiple tokens from each transformer call. Our algorithm relies on the observation that the latency of parallel scoring of short continuations, generated by a faster but less powerful draft model, is comparable to that of sampling a single token from the larger target model. This is combined with a novel modified rejection sampling scheme which preserves the distribution of the target model within hardware numerics. We benchmark speculative sampling with Chinchilla, a 70 billion parameter language model, achieving a 2-2.5x decoding speedup in a distributed setup, without compromising the sample quality or making modifications to the model itself.
研究动机与目标
- 推动在极大规模变换器的自回归解码中降低延迟。
- 提出 speculative sampling (SpS),在每次目标模型调用中生成多个草拟令牌。
- 展示 SpS 能在硬件数值范围内保持目标分布,并且无需修改目标模型即可部署。
- 展示在以 Chinchilla 大小为基准的模型上,在自然语言任务中实现显著的加速,同时保持采样质量。
提出的方法
- 使用更快的草拟模型(自回归或并行)生成长度为 K 的简短草拟。
- 用更大的目标模型对草拟的延续进行评分,以获得对数概率分布。
- 应用改进的拒绝采样方案来接受草拟令牌并恢复目标分布。
- 证明该方案保持目标分布(定理 1)。
- 在 4B 草拟模型和 70B 目标模型(Chinchilla)上进行实验,以测量延迟和质量。
- 显示与常见解码方法(nucleus、top-k、temperature)的兼容性以及与其他效率技术结合的潜力。
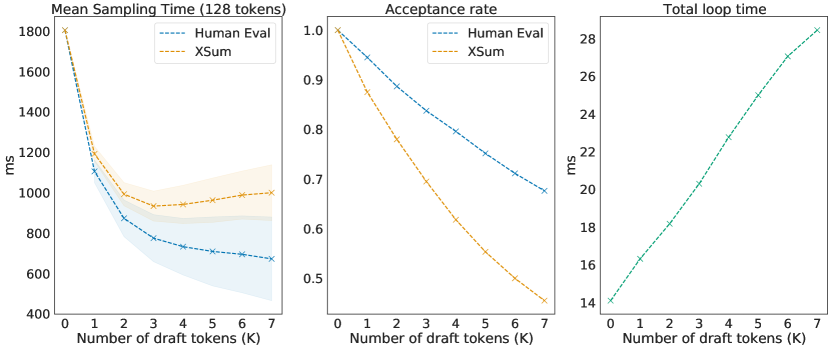
实验结果
研究问题
- RQ1在不修改目标模型的情况下, speculate 采样是否能实现延迟降低?
- RQ2草拟长度 K 与跨任务和解码策略的总体加速之间的权衡如何?
- RQ3草拟令牌的接受率如何依赖于领域和解码设置,样本质量是否保持完好?
主要发现
| 采样方法 | 基准 | 结果 | 平均令牌时间 | 加速比 |
|---|---|---|---|---|
| ArS (Nucleus) | XSum (ROUGE-2) | 0.112 | 14.1ms/Token | 1× |
| SpS (Nucleus) | XSum (ROUGE-2) | 0.114 | 7.52ms/Token | 1.92× |
| ArS (Greedy) | XSum (ROUGE-2) | 0.157 | 14.1ms/Token | 1× |
| SpS (Greedy) | XSum (ROUGE-2) | 0.156 | 7.00ms/Token | 2.01× |
| ArS (Nucleus) | HumanEval (100 Shot) | 45.1% | 14.1ms/Token | 1× |
| SpS (Nucleus) | HumanEval (100 Shot) | 47.0% | 5.73ms/Token | 2.46× |
- 在分布式设置下对 Chinchilla 70B 进行采样时实现 2–2.5× 的解码加速。
- 推测性采样在数值范围内保持目标分布,XSum 与 HumanEval 任务的经验结果与基线相匹配。
- 4B 草拟模型在同一硬件上可达到 1.8 ms/token,而目标模型为 14.1 ms/token,从而实现可观的实际加速。
- 在某些情况下,加速甚至可以超过自回归采样的硬件内存带宽上限(例如在带贪婪 XSum 的 HumanEval 案例)。
- 接受率和效率取决于 K 与领域,最优 K 会随任务而异(例如 XSum 的最优 K 为 K=3)。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。