[论文解读] Adversarial Example Does Good: Preventing Painting Imitation from Diffusion Models via Adversarial Examples
这篇论文为扩散模型定义对抗样本,并提出 AdvDM 通过扰动输入绘画使基于扩散模型的 AI 艺术无法提取特征或模仿风格,通过 Monte Carlo 基于优化及多种版权保护场景进行评估。
Recently, Diffusion Models (DMs) boost a wave in AI for Art yet raise new copyright concerns, where infringers benefit from using unauthorized paintings to train DMs to generate novel paintings in a similar style. To address these emerging copyright violations, in this paper, we are the first to explore and propose to utilize adversarial examples for DMs to protect human-created artworks. Specifically, we first build a theoretical framework to define and evaluate the adversarial examples for DMs. Then, based on this framework, we design a novel algorithm, named AdvDM, which exploits a Monte-Carlo estimation of adversarial examples for DMs by optimizing upon different latent variables sampled from the reverse process of DMs. Extensive experiments show that the generated adversarial examples can effectively hinder DMs from extracting their features. Therefore, our method can be a powerful tool for human artists to protect their copyright against infringers equipped with DM-based AI-for-Art applications. The code of our method is available on GitHub: https://github.com/mist-project/mist.git.
研究动机与目标
- 为人类创作的绘画对抗基于扩散模型的 AI 艺术进行版权保护提供动机。
- 定义扩散模型(DMs)中的对抗样本的形式化框架。
- 设计 AdvDM,通过蒙特卡罗估计生成对抗输入,以阻碍 DM 的特征提取。
- 在 Latent Diffusion Models (LDMs) 上,在文本到图像、风格迁移和图像到图像场景下评估 AdvDM。
- 评估鲁棒性和防御策略,包括预处理防御,对抗 AdvDM。
提出的方法
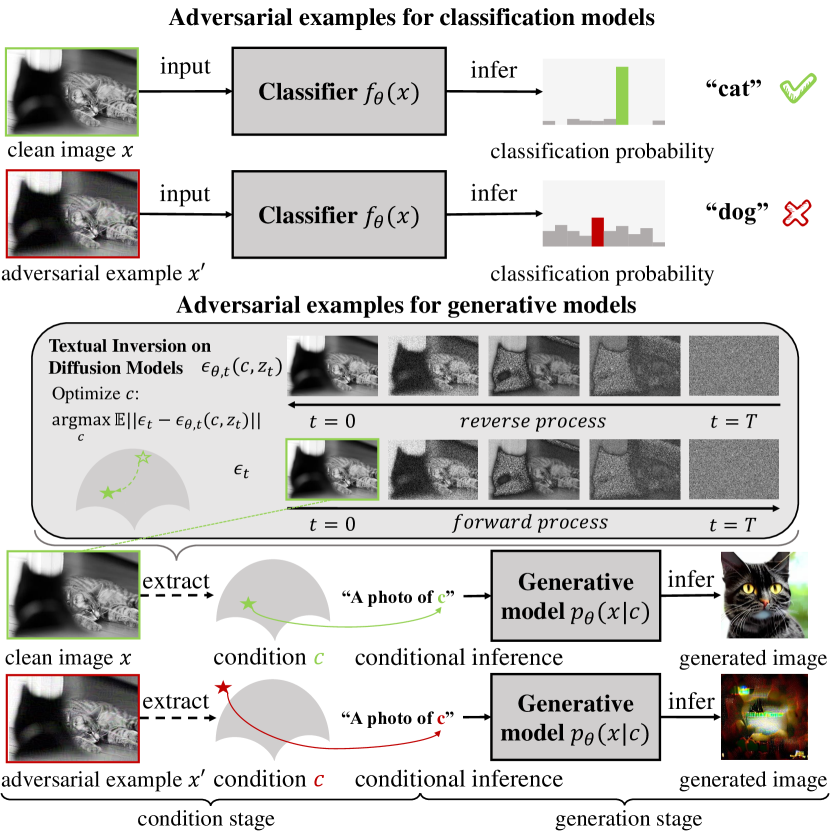
- 将扩散模型的对抗样本定义为 x' = x + delta,且 ||delta|| <= epsilon,通过蒙特卡洛在潜变量扩散步骤上最小化 p_theta(x+delta)。
- 通过对潜变量 x'1:T 的样本(来自后验样分布)求平均的 DM 训练损失来最大化 delta,使用梯度上升。
- 使用 AdvDM:对潜变量进行蒙特卡洛采样的迭代符号梯度步骤来估计目标函数。
- 用条件生成指标(FID、Precision、Recall)在文本到图像、风格迁移和图像到图像任务上进行评估。
- 考察权衡:采样步骤、扰动预算和推理时间;与预处理防御(JPEG、TVM、SR)以及净化(DiffPure)进行比较。
- 核心方程: p_theta(x) = ∫ p_theta(x0:T) dx1:T; 对抗目标函数 max_delta E_{x1:T'~u(x1:T')} L_DM(theta) = -log p_theta(x0:T) (Eq. 7); AdvDM 更新: x0^(i+1) = x0^(i) + alpha * sgn(∇_{x0^(i)} L_DM(...)) (Eq. 9).
实验结果
研究问题
- RQ1对抗性扰动是否能阻止扩散模型提取用于模仿绘画的条件特征(如文本反转提示)?
- RQ2在多个生成场景中,AdvDM 在降低 DM 生成的基于扰动输入的输出质量方面有多有效?
- RQ3在为 DM 生成对抗样本时,实际的权衡有哪些(采样步骤、扰动预算、推理时间)?
- RQ4预处理防御是否能够充分缓解 AdvDM 而不破坏图像语义?
- RQ5AdvDM 是否扩展到商业 DM 系统(如 Stable Diffusion)以及各种条件范式(文本、风格、图像)?
主要发现
| 数据集 | 指标 | LSUN-Cat FID | LSUN-Cat 精确度 | LSUN-Cat 召回率 | LSUN-Sheep FID | LSUN-Sheep 精确度 | LSUN-Sheep 召回率 | LSUN-Airplane FID | LSUN-Airplane 精确度 | LSUN-Airplane 召回率 |
|---|---|---|---|---|---|---|---|---|---|---|
| LSUN-Cat | 无攻击 | 34.94 | 0.5643 | 0.1531 | 32.81 | 0.6378 | 0.1228 | 39.22 | 0.5016 | 0.2765 |
| LSUN-Cat | AdvDM | 127.04 | 0.1708 | 0.061 | 203.5 | 0.0058 | 0.378 | 169.67 | 0.0263 | 0.3235 |
- 对抗性样本显著提高 FID 并降低在扰动输入条件下的文本到图像生成的 Precision,表明对艺术品特征的保护取得成功。
- AdvDM 在风格迁移和图像到图像场景中,显著降低 DM 模仿风格/内容的能力,样本质量下降。
- 增加蒙特卡洛采样能提升攻击效果(更高 FID、更低 Precision),但增加推理时间;主实验中使用40个采样步骤实现平衡。
- 扰动预算小到 4/255 就能显著影响生成质量;更大预算效果更强但运行时间更长。
- 如 JPEG 和 TVM 的预处理防御只能部分缓解 AdvDM;SR 防御对 FID 有更大帮助但对 Precision 的影响不稳定,表明 AdvDM 的语义干扰持续存在。
- 该方法对基于文本反转的条件有效,并能推广到多种基于 DM 的艺术生成工作流,包括对 WikiArt 和 LSUN 数据集的评估。

更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。