[论文解读] AfriQA: Cross-lingual Open-Retrieval Question Answering for African Languages
AfriQA 是首个面向非洲语言的跨语言开放检索问答数据集,包含跨10种语言的12,239个问题,支持在低资源语言中评估 XOR 检索与问答。
African languages have far less in-language content available digitally, making it challenging for question answering systems to satisfy the information needs of users. Cross-lingual open-retrieval question answering (XOR QA) systems -- those that retrieve answer content from other languages while serving people in their native language -- offer a means of filling this gap. To this end, we create AfriQA, the first cross-lingual QA dataset with a focus on African languages. AfriQA includes 12,000+ XOR QA examples across 10 African languages. While previous datasets have focused primarily on languages where cross-lingual QA augments coverage from the target language, AfriQA focuses on languages where cross-lingual answer content is the only high-coverage source of answer content. Because of this, we argue that African languages are one of the most important and realistic use cases for XOR QA. Our experiments demonstrate the poor performance of automatic translation and multilingual retrieval methods. Overall, AfriQA proves challenging for state-of-the-art QA models. We hope that the dataset enables the development of more equitable QA technology.
研究动机与目标
- 通过创建面向非洲语言的从头开始的 XOR 问答数据集,解决非洲语言问答数据不足的问题。
- 提供一个可扩展的基准,覆盖10种非洲语言,以研究跨语言检索与答案生成。
- 评估多种翻译、检索与问答基线,识别当前在非洲语言的 XOR 问答中的局限性。
- 提供对语言特性和标注挑战的分析,以指导未来的数据集创建和模型开发。
提出的方法
- 构建 AfriQA,覆盖10种非洲语言、包含12,239个问题与8,892个问答对。
- 在跨语言开放检索设定下,问题用非洲语言表述,段落在枢轴语言(英语或法语)中检索。
- 通过四阶段标注流程收集数据:问题征集、翻译为枢轴语言、在枢轴语言中对答案进行标注、再翻译回原语言。
- 评估三项 XOR QA 任务:XOR-Retrieve、XOR-PivotLanguageSpan、XOR-Full,使用翻译、检索与阅读器模型。
- 比较基线包括 Google Translate、NLLB、M2M-100、BM25、mDPR 和稀疏-密集混合,以及 AfroXLMR 与 mBERT 基于的阅读器。
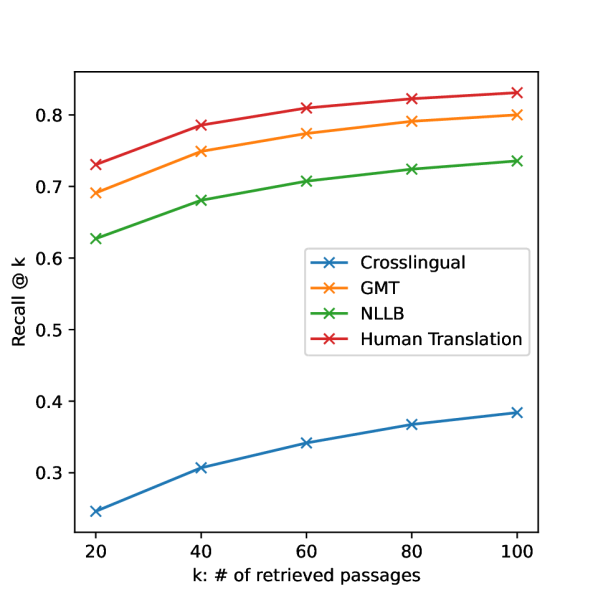
实验结果
研究问题
- RQ1在当前翻译与检索基线下,非洲语言的跨语言开放检索问答性能如何?
- RQ2翻译质量与检索策略如何影响低资源语言的跨语言问答准确性?
- RQ3一种混合稀疏-密集检索方法是否能在非洲语言的 XOR QA 中优于翻译后再检索的基线?
- RQ410种非洲语言的语言特性对问答系统设计与评估有何影响?
主要发现
- 最终的 AfriQA 数据集包含跨10种语言的12,239个问题,及8,892个问答对。
- 只有27%的问题是不可回答的,表明在维基百科的约束下,答案覆盖率相对较高。
- 跨语言检索方法在性能上不及基于翻译的基线,凸显当前跨语言检索在这些语言中的不足。
- 混合稀疏-密集检索在若干语言中相较于仅使用 BM25 或 mDPR 有所提升。
- 评估结果显示 AfriQA 对最先进的问答模型具有挑战性,推动更公平的多语言问答系统的发展。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。