[论文解读] AI for Biomedicine in the Era of Large Language Models
本文综述了大型语言模型在生物医学三类数据类型上的应用——文本、生物序列和脑信号,并讨论信任、个性化和多模态整合等挑战。
The capabilities of AI for biomedicine span a wide spectrum, from the atomic level, where it solves partial differential equations for quantum systems, to the molecular level, predicting chemical or protein structures, and further extending to societal predictions like infectious disease outbreaks. Recent advancements in large language models, exemplified by models like ChatGPT, have showcased significant prowess in natural language tasks, such as translating languages, constructing chatbots, and answering questions. When we consider biomedical data, we observe a resemblance to natural language in terms of sequences: biomedical literature and health records presented as text, biological sequences or sequencing data arranged in sequences, or sensor data like brain signals as time series. The question arises: Can we harness the potential of recent large language models to drive biomedical knowledge discoveries? In this survey, we will explore the application of large language models to three crucial categories of biomedical data: 1) textual data, 2) biological sequences, and 3) brain signals. Furthermore, we will delve into large language model challenges in biomedical research, including ensuring trustworthiness, achieving personalization, and adapting to multi-modal data representation
研究动机与目标
- 推动在文本数据、生物序列和脑信号的生物医学知识发现中探索大型语言模型。
- 综述目前面向不同数据模态的生物医学大型语言模型及架构。
- 识别信任性、个性化和多模态生物医学人工智能的挑战与考量。
- 突出生物医学大型语言模型在临床和研究环境中的应用及下游任务。
提出的方法
- 综述并整合三类数据类别的生物医学大型语言模型文献:文本数据、生物序列和脑信号。
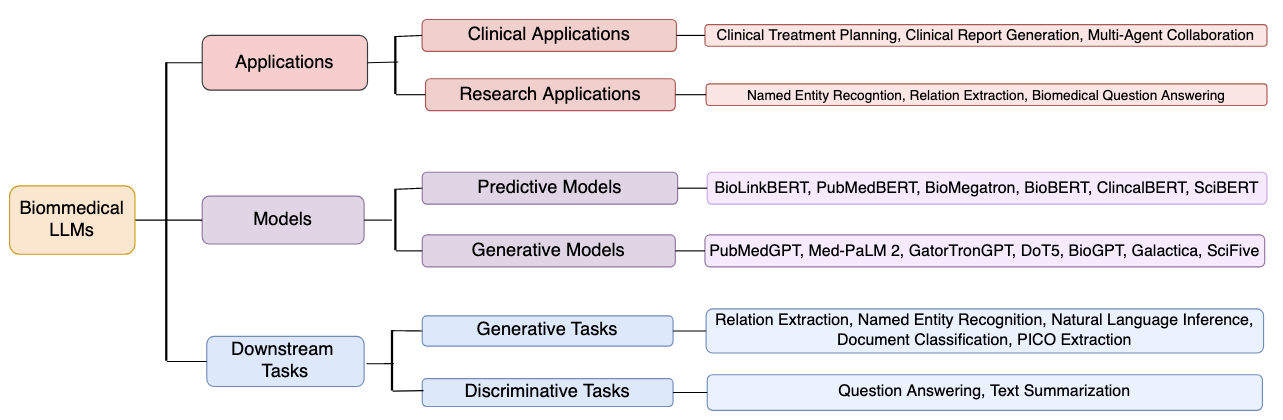
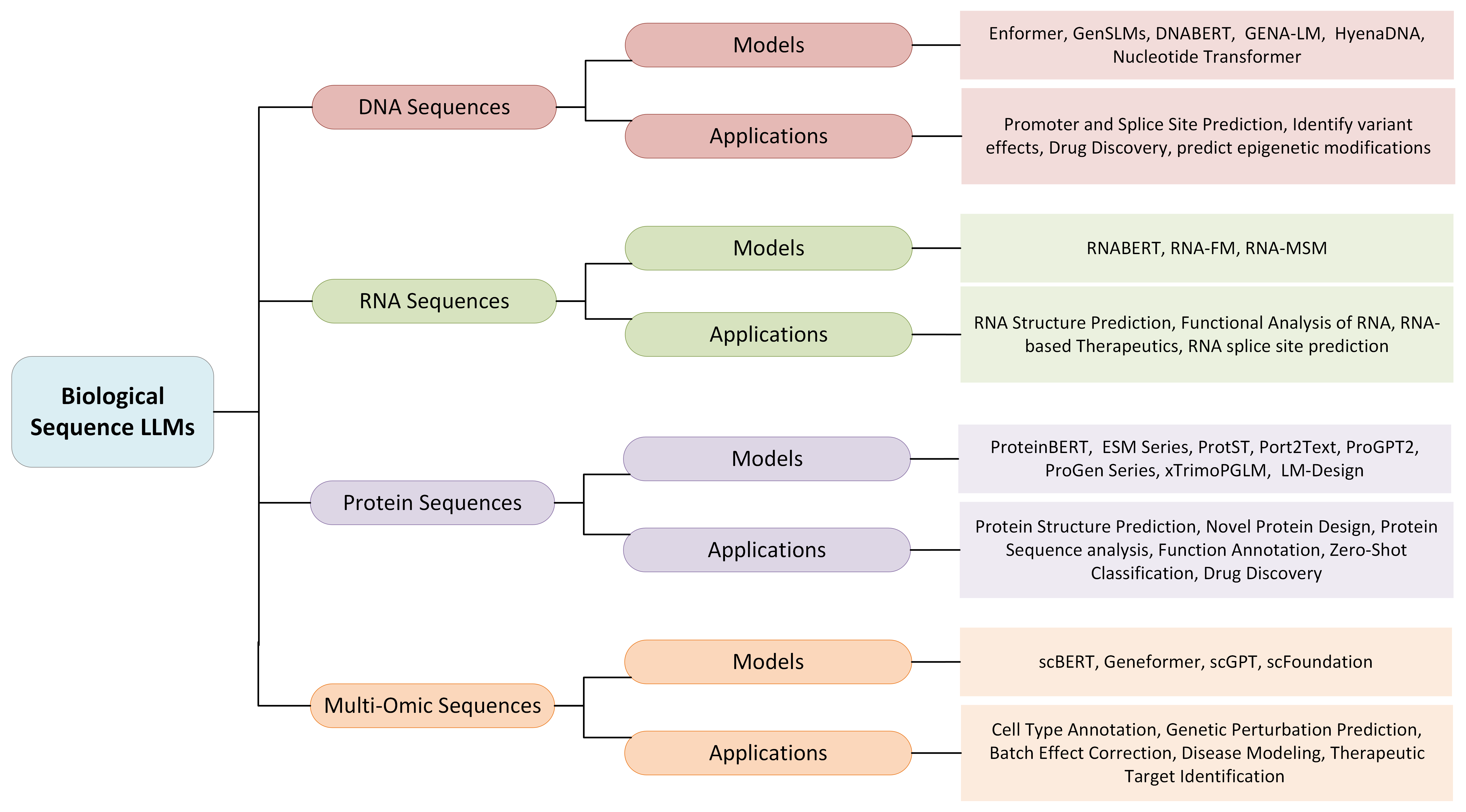
- 总结每种模态的代表性模型与预训练策略(如 SciBERT、BioBERT、BioGPT、GenSLMs、DNABERT、RNABERT、ESM、ProtST 等)。
- 讨论信息抽取、问答、关系抽取以及蛋白质/ RNA 序列的理解与生成方面的应用。
- 概述挑战,包括可信度、个性化以及多模态数据表示。
实验结果
研究问题
- RQ1将LLMs应用于生物医学文本数据、序列和脑信号时,目前的能力和局限性有哪些?
- RQ2对于每种生物医学数据模态,哪些模型和预训练方法最有效?
- RQ3为确保基于LLM的生物医学研究与实践的可信、个性化和多模态,需要解决哪些挑战?
主要发现
- 生物医学大型语言模型覆盖文本数据、序列(DNA、RNA、蛋白质、多组学)和脑信号,并具有专门的模型与预训练体系。
- 大量领域特定模型(如 SciBERT、BioBERT、PubMedBERT、BioLinkBERT、Galactica、BioGPT、DoT5、GenSLMs、DNABERT、RNABERT、RNA-MSM、ESM/ESM-2、ProtST 等)在三个数据类别的多样任务上已达到或接近最先进的性能。
- 应用包括信息抽取、问答、关系抽取,以及用于生物医学发现的高级序列/功能预测与设计。
- 本文强调的挑战包括确保可信度、实现个性化以及将模型适应于多模态生物医学数据。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。