[论文解读] Analyzing Leakage of Personally Identifiable Information in Language Models
本文提出三种PII泄露攻击(提取、重构、推断),在对法律、健康和电子邮件领域微调的GPT-2变体上进行有无防御的评估,并分析涂抹/差分隐私如何影响PII泄露。
Language Models (LMs) have been shown to leak information about training data through sentence-level membership inference and reconstruction attacks. Understanding the risk of LMs leaking Personally Identifiable Information (PII) has received less attention, which can be attributed to the false assumption that dataset curation techniques such as scrubbing are sufficient to prevent PII leakage. Scrubbing techniques reduce but do not prevent the risk of PII leakage: in practice scrubbing is imperfect and must balance the trade-off between minimizing disclosure and preserving the utility of the dataset. On the other hand, it is unclear to which extent algorithmic defenses such as differential privacy, designed to guarantee sentence- or user-level privacy, prevent PII disclosure. In this work, we introduce rigorous game-based definitions for three types of PII leakage via black-box extraction, inference, and reconstruction attacks with only API access to an LM. We empirically evaluate the attacks against GPT-2 models fine-tuned with and without defenses in three domains: case law, health care, and e-mails. Our main contributions are (i) novel attacks that can extract up to 10$ imes$ more PII sequences than existing attacks, (ii) showing that sentence-level differential privacy reduces the risk of PII disclosure but still leaks about 3% of PII sequences, and (iii) a subtle connection between record-level membership inference and PII reconstruction. Code to reproduce all experiments in the paper is available at https://github.com/microsoft/analysing_pii_leakage.
研究动机与目标
- 有必要研究语言模型中的PII泄露,不仅仅是一般记忆,尤其关注直接或上下文PII暴露。
- 建立一个正式的分类法和基于博弈的PII泄露定义,覆盖提取、重构和推断。
- 在三个领域微调的GPT-2变体上,使用黑盒API访问,在无防御、清洗和DP训练模型中进行经验评估PII泄露。
- 量化隐私-实用权衡,并为防御设计和政策提供可操作的见解。
提出的方法
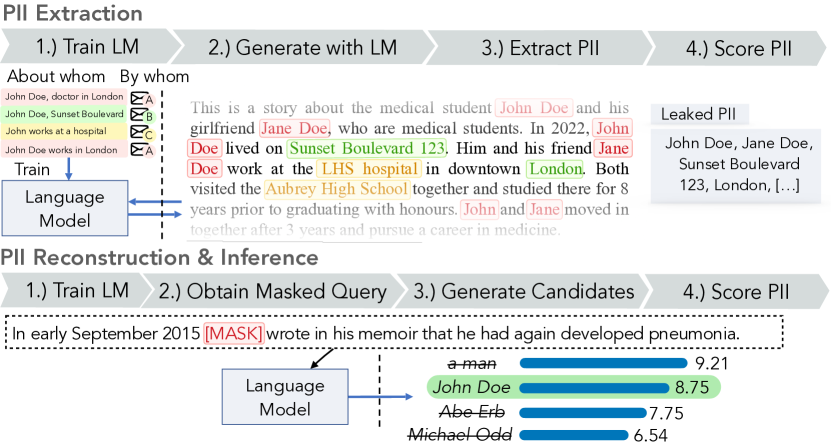
- 提出三种PII泄露威胁:提取、重构和推断,给出正式的基于博弈的定义。
- 定义PII泄露的度量标准,包括在黑盒LM访问下的可提取性和召回率。
- 开发具体攻击算法,近似理想泄露,利用后缀/前缀信息和掩码输出。
- 在法律、健康护理和电子邮件领域微调的GPT-2变体上,在无防御、清洗和DP训练设置下评估攻击。
- 分析清洗和DP如何影响模型困惑度(perplexity)和PII泄露风险。
- 提供复现实验的代码。
实验结果
研究问题
- RQ1在通过黑盒API访问进行提取、重构和推断攻击下,语言模型泄露了多少PII?
- RQ2PII清洗或差分隐私是否足以缓解PII泄露,以及由此产生的隐私/实用性权衡?
- RQ3记录级成员资格推断与PII重构在实践中的关系?
- RQ4在记录级别的DP防御是否能限制PII泄露,同时不严重削弱模型的实用性?
主要发现
- 这些攻击可以提取比现有攻击多出多达10×的PII序列。
- 句子级差分隐私降低PII泄露风险,但仍会泄露约3%的PII序列。
- 记录级成员资格推断与PII重构之间存在微妙的联系。
- DP提供了显著但不完全的PII泄露保护,强调需要互补防御。
- 清洗和DP的权衡可以调优以平衡隐私和实用性,暗示在存在DP时可采用组合或更轻的清洗。

更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。