[论文解读] ARAGOG: Advanced RAG Output Grading
简要结论:本文在检索增强生成(RAG)技术上基准测试检索精度和答案相似性,发现 HyDE 和 LLM 基于再排序提升检索质量,而句子窗口检索在检索精度方面表现最佳,部分技术未超越 Naive RAG。
Retrieval-Augmented Generation (RAG) is essential for integrating external knowledge into Large Language Model (LLM) outputs. While the literature on RAG is growing, it primarily focuses on systematic reviews and comparisons of new state-of-the-art (SoTA) techniques against their predecessors, with a gap in extensive experimental comparisons. This study begins to address this gap by assessing various RAG methods' impacts on retrieval precision and answer similarity. We found that Hypothetical Document Embedding (HyDE) and LLM reranking significantly enhance retrieval precision. However, Maximal Marginal Relevance (MMR) and Cohere rerank did not exhibit notable advantages over a baseline Naive RAG system, and Multi-query approaches underperformed. Sentence Window Retrieval emerged as the most effective for retrieval precision, despite its variable performance on answer similarity. The study confirms the potential of the Document Summary Index as a competent retrieval approach. All resources related to this research are publicly accessible for further investigation through our GitHub repository ARAGOG (https://github.com/predlico/ARAGOG). We welcome the community to further this exploratory study in RAG systems.
研究动机与目标
- 评估一系列先进 RAG 技术对检索精度和答案相似性的影响。
- 确定在一个 RAG 流水线中,哪些检索与生成组件的组合能带来最强的性能。
- 就检索质量、延迟和成本之间的权衡提供实用指导。
- 使实验流水线对外公开,以便社区复现和扩展。
提出的方法
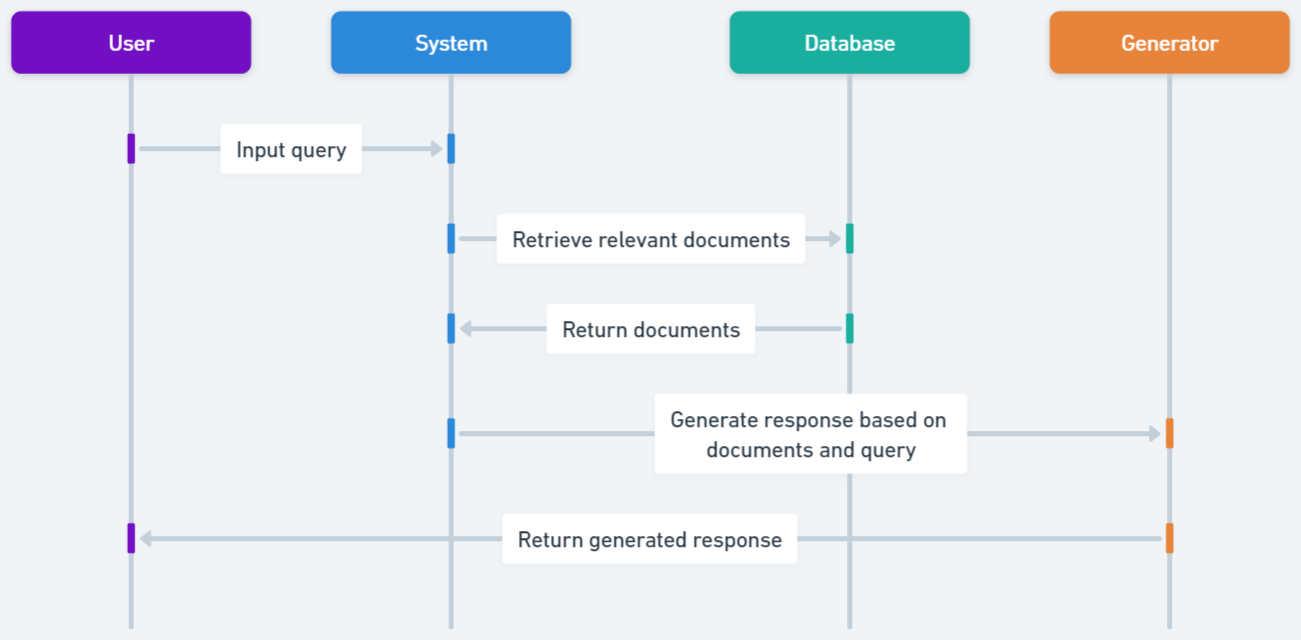
- 评估包括句子窗口检索、文档摘要索引、HyDE、Multi-query、MMR、Cohere 再排序和 LLM 再排序在内的广泛 RAG 技术。
- 使用不同的分块策略(512 tokens 的分块、50-token 的重叠、3 段落窗口、3072-token 摘要)来构建向量数据库,以反映每种方法的需求。
- 以 GPT-3.5-turbo 作为生成器,并通过 Tonic Validate 指标使用 LLM 进行评估。
- 在每种技术上进行 10 次运行,以衡量检索精度和答案相似性(0-5),以缓解 LLM 的变异性。
- 应用方差分析(ANOVA)和 Tukey 的 HSD 进行检索精度差异的统计显著性检验。
实验结果
研究问题
- RQ1相对于 Naive RAG,哪些 RAG 技术能显著提高检索精度?
- RQ2RAG 技术在检索精度、答案相似性和成本之间如何权衡?
- RQ3如 HyDE 或再排序器等技术,是否在不同数据集和分块方案下都优于基线?
- RQ4在不同配置下,句子窗口检索在检索精度方面是否始终优越?
主要发现
- HyDE 和 LLM 重新排序显著提高了相对于 Naive RAG 的检索精度。
- 句子窗口检索在检索精度方面表现出高水平,常常优于经典向量数据库基线。
- MMR 和 Cohere 重新排序在检索精度方面对 Naive RAG 的改进很少甚至没有。
- 多查询方法在检索精度方面不如基线 Naive RAG。
- 文档摘要索引方法与最佳经典 VDB 设置相当,但需要前期摘要工作。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。