[论文解读] ARB: Advanced Reasoning Benchmark for Large Language Models
ARB 是一个具有挑战性的、面向研究生水平的推理基准,涵盖数学、物理、化学、生物学和法律。它引入基于评分标准的自我评估方法,并显示当前的大语言模型在高级定量任务上仍表现不佳。
Large Language Models (LLMs) have demonstrated remarkable performance on various quantitative reasoning and knowledge benchmarks. However, many of these benchmarks are losing utility as LLMs get increasingly high scores, despite not yet reaching expert performance in these domains. We introduce ARB, a novel benchmark composed of advanced reasoning problems in multiple fields. ARB presents a more challenging test than prior benchmarks, featuring problems in mathematics, physics, biology, chemistry, and law. As a subset of ARB, we introduce a challenging set of math and physics problems which require advanced symbolic reasoning and domain knowledge. We evaluate recent models such as GPT-4 and Claude on ARB and demonstrate that current models score well below 50% on more demanding tasks. In order to improve both automatic and assisted evaluation capabilities, we introduce a rubric-based evaluation approach, allowing GPT-4 to score its own intermediate reasoning steps. Further, we conduct a human evaluation of the symbolic subset of ARB, finding promising agreement between annotators and GPT-4 rubric evaluation scores.
研究动机与目标
- 将 ARB 作为一个新基准,用于评估跨多个领域的专家级、研究生水平的推理。
- 提供来自专业/研究生材料的多样化题目集合(数学、物理、生物、化学、法律)。
- 提出并验证基于评分标准的评估方法,能够对中间推理步骤进行自我评估。
- 展示模型性能(GPT-4、GPT-3.5、Claude)并分析错误类型与评估可靠性。
提出的方法
- 基准测试包含三种题型:选择题、简答题和开放性回答题,其中简答题/开放性回答题比例更高。
- 题目来源于标准化考试、习题集、研究生考试以及律师/法律材料,以确保研究生水平难度。
- 对选择题和数值答案使用自动解析与评分程序,对符号答案使用基于 SymPy 的解析。
- 引入基于模型的评分标准评估方法,其中 GPT-4 根据参考解生成评分标准并用其对解答进行评分。
- 在人类评估对符号子集进行评估,以与基于评分标准的分数进行比较,评估覆盖度和分值分配。
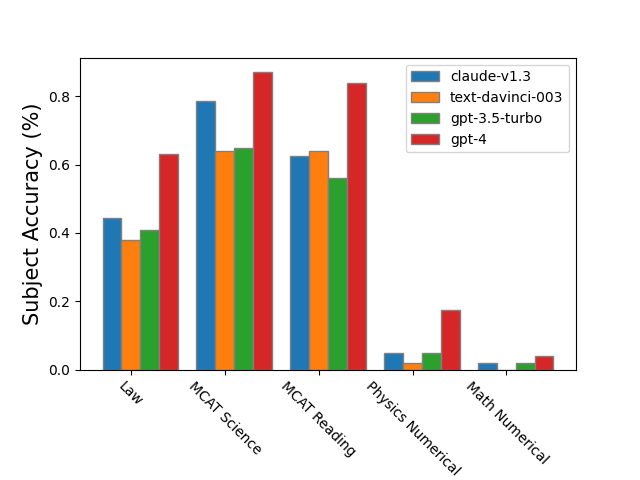
实验结果
研究问题
- RQ1当前的 LLM(例如 GPT-4、GPT-3.5、Claude)在 ARB 的跨领域高级推理任务上的表现如何?
- RQ2基于模型的、由评分标准生成的评估能否可靠地近似符号性和证明式问题的人类评分?
- RQ3LLMs 在高级数学和物理问题上会出现哪些类型的错误?这些错误如何随题型而异?
- RQ4通过评分标准进行自我评估是否与人类判断相关,并提高自动评分的鲁棒性?
主要发现
- 当前模型在 ARB 的许多要求高的定量任务上远低于专家水平。
- GPT-4 可以简化复杂表达式,但在长上下文的算术和符号操作上仍然困难。
- 符号性和证明式问题在各模型中都表现出大量失败率,且在若干类别中报告了明确的基于表格的百分比。
- 由 GPT-4 进行的基于评分标准的评估与人类评分呈中等偏高的相关性(例如物理符号、数学符号和证明式问题)。
- GPT-4 生成的评分标准覆盖关键解题步骤,但可能分配分值不当;基于评分标准的评分减少评估工作量,并与人工评分保持一致。
- 通过评分标准的基于模型的评估作为正确性的自动代理是有前景的,尽管不能完全替代人工评分。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。