[论文解读] Assessing Look-Ahead Bias in Stock Return Predictions Generated By GPT Sentiment Analysis
本文揭示了来自金融头条的基于GPT的情绪交易信号中的前瞻偏差和分散效应,指出对公司名称进行匿名化可以降低样本内偏差,并可能提高样本外表现,尤其是对于规模较大的公司。
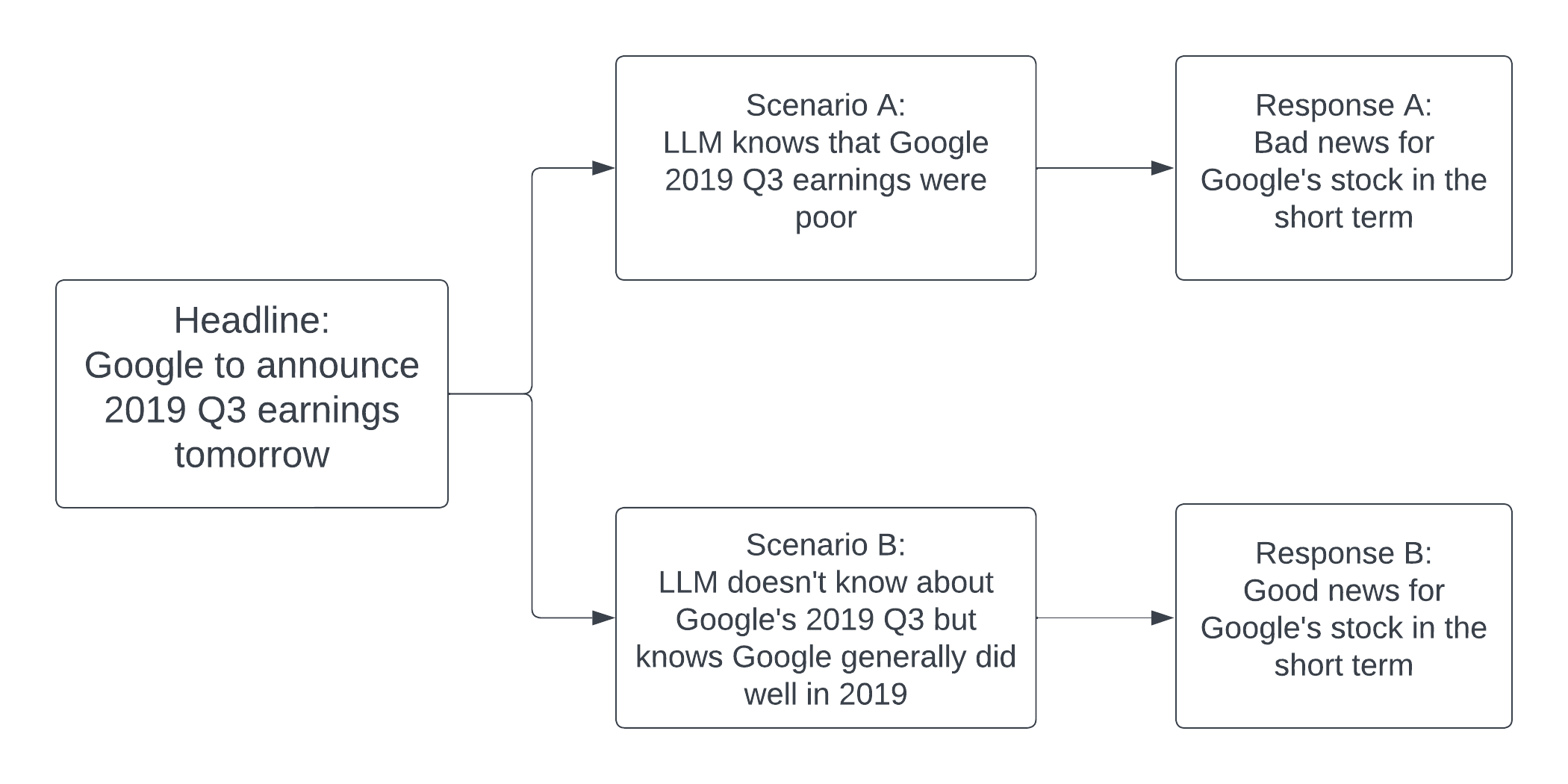
Large language models (LLMs), including ChatGPT, can extract profitable trading signals from the sentiment in news text. However, backtesting such strategies poses a challenge because LLMs are trained on many years of data, and backtesting produces biased results if the training and backtesting periods overlap. This bias can take two forms: a look-ahead bias, in which the LLM may have specific knowledge of the stock returns that followed a news article, and a distraction effect, in which general knowledge of the companies named interferes with the measurement of a text's sentiment. We investigate these sources of bias through trading strategies driven by the sentiment of financial news headlines. We compare trading performance based on the original headlines with de-biased strategies in which we remove the relevant company's identifiers from the text. In-sample (within the LLM training window), we find, surprisingly, that the anonymized headlines outperform, indicating that the distraction effect has a greater impact than look-ahead bias. This tendency is particularly strong for larger companies--companies about which we expect an LLM to have greater general knowledge. Out-of-sample, look-ahead bias is not a concern but distraction remains possible. Our proposed anonymization procedure is therefore potentially useful in out-of-sample implementation, as well as for de-biased backtesting.
研究动机与目标
- 动机化问题:在以金融新闻情绪驱动的LLM交易中存在前瞻偏差。
- 开发一种匿名化方法,从头条中移除实体标识符。
- 比较原始头条与匿名化头条在样本内和样本外的交易表现。
- 评估公司规模如何影响基于GPT的分数的偏差和预测能力。
- 为未来LLM回测提供切实可行的去偏指南。
提出的方法
- 使用固定提示对头条进行分类,将其归类为对股价有利/中性/不利。
- 从GPT分数计算日交易信号,并评估多头策略、空头策略以及多空策略。
- 通过模糊匹配和知识图谱增强,将头条中的公司标识符及相关产品/服务替换为匿名化。
- 比较抓取数据与Thomson Reuters头条集在样本内和样本外的表现。
- 分析均值收益、t检验及误差分布,以诊断前瞻偏差与分心效应。
实验结果
研究问题
- RQ1对公司标识符进行匿名化是否会降低基于GPT的情感交易中的前瞻偏差?
- RQ2关于公司的一般知识所导致的分散效应是否在样本内回测中比前瞻偏差更具影响力?
- RQ3公司规模如何影响基于GPT的交易信号的偏差与表现?
- RQ4去偏(匿名化)的信号是否提升样本外表现?
- RQ5在原始提示与匿名化提示下,GPT情绪分数的预测力是什么?
主要发现
- 样本内,替换后的头条在抓取数据和Thomson Reuters数据中均获得比原始头条更高的平均收益(抓取数据均值 30.97 对 25.08;差异 5.89 bp/day;p=0.017;Thomson Reuters 数据均值 13.84 对 10.74;差异 4.37 bp/day;p=0.017)。
- 样本外,抓取数据原始头条的均值高于替换头条(16.32 对 11.09 bp/day;在传统显著性水平下不显著),而Thomson Reuters数据为 12.23 对 6.07 bp/day(p≈0.064)。
- 这一样本内结果出人意料,表明分散效应超过前瞻偏差,尤其是对规模较大的公司,匿名化的效果更明显。
- 分类分析表明,当替换回应为中性时,原始回应更容易出错,导致在原始提示下的样本内损失更大。
- 样本外结果表明前瞻偏差并非主要问题,但分散效应仍然存在,对于大盘股,匿名化有改善表现的证据。
- 将匿名化方法作为去偏回测的实用工具,并可能改善样本外表现。

更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。