[论文解读] Asynchronous Multi-Agent Reinforcement Learning for Efficient Real-Time Multi-Robot Cooperative Exploration
ACE 将 MAPPO 扩展到异步 setting,含行动延迟随机化和多塔 CNN 策略,以实现实时协同探索;在网格、真实世界和 Habitat 环境中,优于基于规划的和同步 MARL 的基线。
We consider the problem of cooperative exploration where multiple robots need to cooperatively explore an unknown region as fast as possible. Multi-agent reinforcement learning (MARL) has recently become a trending paradigm for solving this challenge. However, existing MARL-based methods adopt action-making steps as the metric for exploration efficiency by assuming all the agents are acting in a fully synchronous manner: i.e., every single agent produces an action simultaneously and every single action is executed instantaneously at each time step. Despite its mathematical simplicity, such a synchronous MARL formulation can be problematic for real-world robotic applications. It can be typical that different robots may take slightly different wall-clock times to accomplish an atomic action or even periodically get lost due to hardware issues. Simply waiting for every robot being ready for the next action can be particularly time-inefficient. Therefore, we propose an asynchronous MARL solution, Asynchronous Coordination Explorer (ACE), to tackle this real-world challenge. We first extend a classical MARL algorithm, multi-agent PPO (MAPPO), to the asynchronous setting and additionally apply action-delay randomization to enforce the learned policy to generalize better to varying action delays in the real world. Moreover, each navigation agent is represented as a team-size-invariant CNN-based policy, which greatly benefits real-robot deployment by handling possible robot lost and allows bandwidth-efficient intra-agent communication through low-dimensional CNN features. We first validate our approach in a grid-based scenario. Both simulation and real-robot results show that ACE reduces over 10% actual exploration time compared with classical approaches. We also apply our framework to a high-fidelity visual-based environment, Habitat, achieving 28% improvement in exploration efficiency.
研究动机与目标
- 在异步动作执行下,激发多种异质机器人之间的实时协同探索。
- 开发一个处理行动延迟和离线代理而不阻塞探索的异步 MARL 框架。
- 提出一种随团队规模扩展且最小化带宽的高效通信策略。
- 在基于网格、真实世界和 Habitat(基于视觉)环境中展示更高的探索效率。
提出的方法
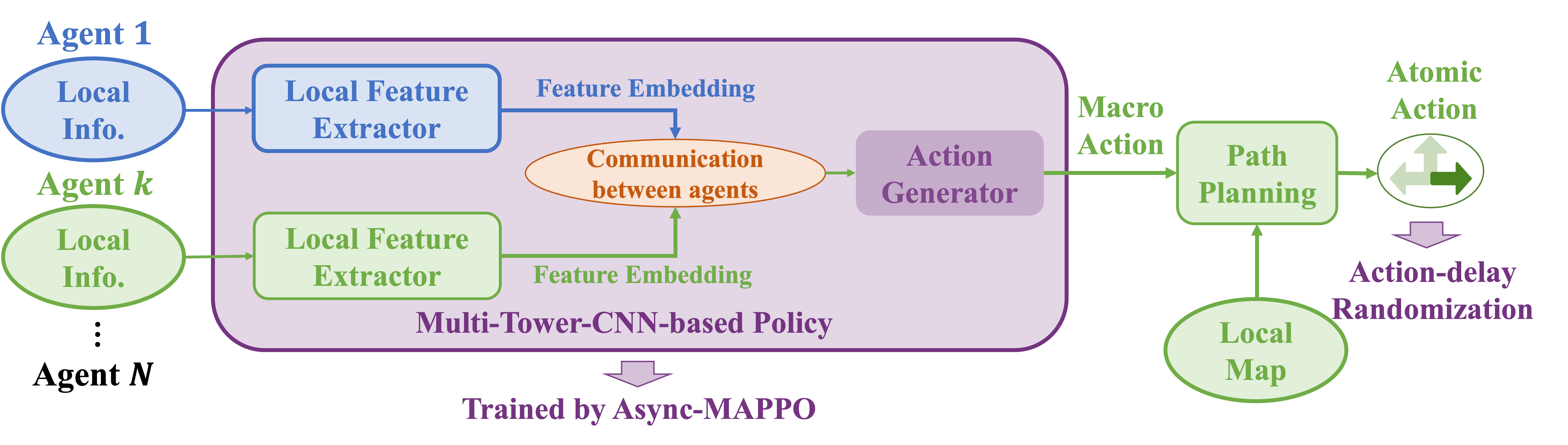
- 将 MAPPO 扩展为 Async-MAPPO,以支持异步行动决策和每个代理的经验缓冲区。
- 在仿真中引入行动延迟随机化,以提高对不同延迟的 sim-to-real 泛化。
- 提出基于 Multi-tower-CNN 的策略(MCP),具有本地 CNN 特征、基于注意力的关系编码器,以及输出宏动作的解码器。
- 采用带宏动作(全局目标)和原子动作的 Dec-POSMDP 形式,支持双层次行动执行。
- 使用权重共享策略和受限特征通信来应对不同的团队规模,并实现对现实世界部署的鲁棒性。

实验结果
研究问题
- RQ1如何将 MARL 适配于用于多机器人协同探索的异步行动执行?
- RQ2行动延迟随机化是否改善 sim-to-real 迁移以及对现实世界延迟的鲁棒性?
- RQ3基于 CNN、尺寸不变的策略是否能够在有限带宽条件下高效协调多机器人?
- RQ4在不同环境中,异步 ACE 相对于基于规划的和同步 MARL 基线的性能提升是多少?
- RQ5ACE 如何处理探索过程中代理离线的情景?
主要发现
- 与经典基于规划的方法相比,ACE 将真实世界探索时间降低超过 10%。
- 在 Habitat(基于视觉的环境)中,ACE 的探索效率提升了 28%。
- 在两台机器人进行的真实世界测试中,ACE 相比 MAPPO 基线将探索时间降低 10.07%。
- 在真实世界实验中,相对最快的基于规划的方法(Nearest),ACE 将探索时间降低 33.86%。
- ACE 能推广到代理损失情景(N1 至 N2),探索速度约快 10%,且重叠更低,与基线相比。
- ACE 在各设置下保持具有竞争力的累积覆盖率(ACS)并降低重叠,同时实现更快完成。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。