[论文解读] AugGPT: Leveraging ChatGPT for Text Data Augmentation
AugGPT 使用 ChatGPT 为每个输入句子生成六个语义相关的增广变体,与 BERT 结合后可提升小样本文本分类的性能。该方法在多个数据集上优于现有的增广基线。
Text data augmentation is an effective strategy for overcoming the challenge of limited sample sizes in many natural language processing (NLP) tasks. This challenge is especially prominent in the few-shot learning scenario, where the data in the target domain is generally much scarcer and of lowered quality. A natural and widely-used strategy to mitigate such challenges is to perform data augmentation to better capture the data invariance and increase the sample size. However, current text data augmentation methods either can't ensure the correct labeling of the generated data (lacking faithfulness) or can't ensure sufficient diversity in the generated data (lacking compactness), or both. Inspired by the recent success of large language models, especially the development of ChatGPT, which demonstrated improved language comprehension abilities, in this work, we propose a text data augmentation approach based on ChatGPT (named AugGPT). AugGPT rephrases each sentence in the training samples into multiple conceptually similar but semantically different samples. The augmented samples can then be used in downstream model training. Experiment results on few-shot learning text classification tasks show the superior performance of the proposed AugGPT approach over state-of-the-art text data augmentation methods in terms of testing accuracy and distribution of the augmented samples.
研究动机与目标
- Motivate data augmentation to address small labeled datasets in NLP, especially in few-shot learning.
- Propose a ChatGPT-based augmentation pipeline to produce faithful and diverse samples.
- Show that augmenting with ChatGPT improves downstream classifier accuracy across multiple domains.
- Investigate faithfulness and compactness of augmented samples.
提出的方法
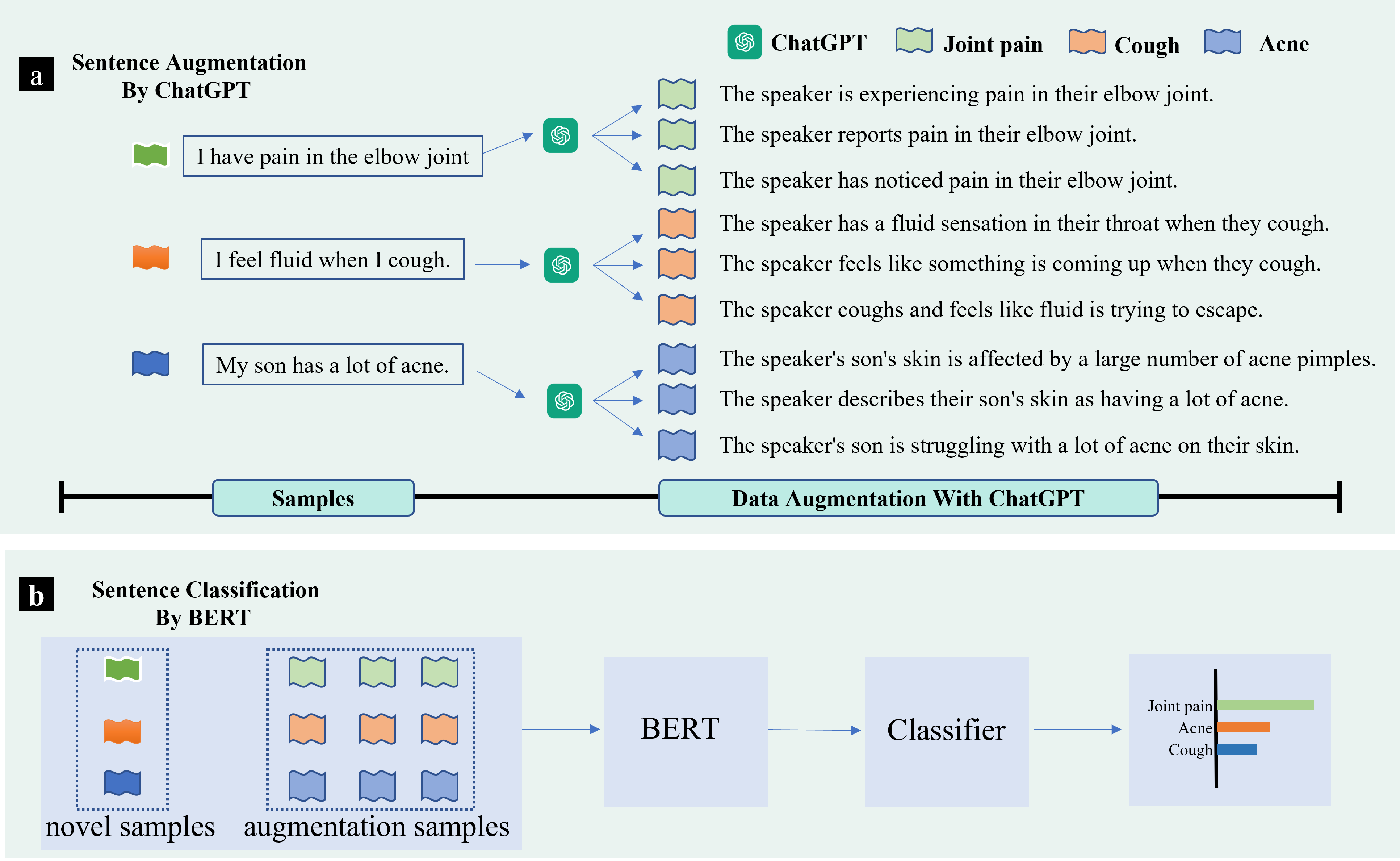
- AugGPT augments each input sentence with six paraphrase-like variants generated by ChatGPT.
- Fine-tune a BERT-based classifier on the base (larger) dataset, then train with augmented novel data (D_n_aug).
- ChatGPT augmentation is powered by GPT-3/ChatGPT with RLHF, including SFT, Reward Modeling, and PPO-based RL (PPO-ptx).
- The objective function combines cross-entropy loss with a contrastive loss to pull same-class representations together and push different-class representations apart.
- Equation-driven components: L_CE = cross-entropy loss; L_CL = contrastive loss; L = L_CE + lambda L_CL.
- Baseline comparisons include a broad set of traditional and contextual augmentation methods.
实验结果
研究问题
- RQ1Can ChatGPT-generated augmentations preserve semantic labels (faithfulness) while increasing diversity (compactness)?
- RQ2Do augmentations improve few-shot text classification accuracy compared to traditional methods?
- RQ3How does AugGPT perform across general-domain and biomedical-domain datasets?
- RQ4What is the impact of combining augmentation with contrastive learning on representation quality?
主要发现
| Data Augmentation | Amazon (BERT) | Amazon (BERT+C) | Symptoms (BERT) | Symptoms (BERT+C) | PubMed20K (BERT) | PubMed20K (BERT+C) |
|---|---|---|---|---|---|---|
| 原始 | 0.734 | 0.745 | 0.636 | 0.606 | 0.792 | 0.798 |
| BackTranslationAug | 0.757 | 0.748 | 0.778 | 0.747 | 0.812 | 0.83 |
| ContextualWordAugUsingBert(Insert) | 0.761 | 0.750 | 0.697 | 0.677 | 0.802 | 0.811 |
| ContextualWordAugUsingBert(Substitute) | 0.745 | 0.730 | 0.727 | 0.667 | 0.782 | 0.782 |
| ContextualWordAugUsingDistilBERT(Insert) | 0.759 | 0.762 | 0.707 | 0.747 | 0.796 | 0.796 |
| ContextualWordAugUsingDistilBERT(Substitute) | 0.787 | 0.766 | 0.667 | 0.646 | 0.797 | 0.800 |
| ContextualWordAugUsingRoBERTa(Insert) | 0.775 | 0.768 | 0.758 | 0.707 | 0.815 | 0.814 |
| ContextualWordAugUsingRoBERTa(Substitute) | 0.745 | 0.730 | 0.727 | 0.667 | 0.782 | 0.782 |
| CounterFittedEmbeddingAug | 0.754 | 0.741 | 0.667 | 0.626 | 0.805 | 0.805 |
| InsertCharAugmentation | 0.771 | 0.775 | 0.404 | 0.475 | 0.826 | 0.831 |
| InsertWordByGoogleNewsEmbeddings | 0.816 | 0.794 | 0.636 | 0.677 | 0.786 | 0.784 |
| KeyboardAugmentation | 0.764 | 0.766 | 0.545 | 0.505 | 0.809 | 0.815 |
| OCRAugmentation | 0.775 | 0.782 | 0.768 | 0.778 | 0.789 | 0.789 |
| PPDBSynonymAug | 0.691 | 0.690 | 0.697 | 0.758 | 0.795 | 0.829 |
| SpellingAugmentation | 0.727 | 0.736 | 0.697 | 0.707 | 0.808 | 0.811 |
| SubstituteCharAugmentation | 0.762 | 0.768 | 0.535 | 0.586 | 0.816 | 0.821 |
| SubstituteWordByGoogleNewsEmbeddings | 0.729 | 0.741 | 0.727 | 0.727 | 0.807 | 0.822 |
| SwapCharAugmentation | 0.762 | 0.766 | 0.475 | 0.485 | 0.797 | 0.801 |
| SwapWordAug | 0.771 | 0.766 | 0.687 | 0.727 | 0.798 | 0.794 |
| WordNetSynonymAug | 0.805 | 0.798 | 0.616 | 0.758 | 0.761 | 0.757 |
| ChatGPT (2-shot) | 0.753 | 0.980 | 0.748 | - | - | - |
| AugGPT | 0.816 | 0.826 | 0.889 | 0.899 | 0.835 | 0.835 |
- AugGPT achieves higher testing accuracy than state-of-the-art augmentation baselines across Amazon, Symptoms, and PubMed20K datasets.
- Augmented samples with ChatGPT show improved diversity while maintaining alignment with original labels (faithfulness).
- In ablation studies, AugGPT outperforms many non-LLM augmentation techniques (e.g., back-translation, contextual word augmentations, synonym-based methods).
- The method yields sizable gains even in 2-shot ChatGPT settings and when integrated with BERT-based fine-tuning on augmented data.
- The approach demonstrates strong performance gains in both general-domain and clinical/NLP benchmarks.
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。