[论文解读] Auto-GPT for Online Decision Making: Benchmarks and Additional Opinions
本论文在真实世界在线决策任务(WebShop 和 ALFWorld)上基准测试 Auto-GPT 风格代理,并引入 Additional Opinions 算法,在提示中注入外部专家模型的建议以提升性能,特别是在 GPT-4 情况下。
Auto-GPT is an autonomous agent that leverages recent advancements in adapting Large Language Models (LLMs) for decision-making tasks. While there has been a growing interest in Auto-GPT stypled agents, questions remain regarding the effectiveness and flexibility of Auto-GPT in solving real-world decision-making tasks. Its limited capability for real-world engagement and the absence of benchmarks contribute to these uncertainties. In this paper, we present a comprehensive benchmark study of Auto-GPT styled agents in decision-making tasks that simulate real-world scenarios. Our aim is to gain deeper insights into this problem and understand the adaptability of GPT-based agents. We compare the performance of popular LLMs such as GPT-4, GPT-3.5, Claude, and Vicuna in Auto-GPT styled decision-making tasks. Furthermore, we introduce the Additional Opinions algorithm, an easy and effective method that incorporates supervised/imitation-based learners into the Auto-GPT scheme. This approach enables lightweight supervised learning without requiring fine-tuning of the foundational LLMs. We demonstrate through careful baseline comparisons and ablation studies that the Additional Opinions algorithm significantly enhances performance in online decision-making benchmarks, including WebShop and ALFWorld.
研究动机与目标
- 研究 Auto-GPT 风格代理在真实世界在线决策任务中的表现。
- 在 Auto-GPT 配置中比较多种大语言模型(GPT-4、GPT-3.5、Claude、Vicuna)。
- 提出并评估使用外部专家模型作为意见提供者的 Additional Opinions 算法。
- 通过消融和基线研究展示轻量级监督是否能在不进行微调的情况下提升性能。
提出的方法
- 在两个在线决策任务中对 Auto-GPT 进行最小提示改进的适配。
- 将行动表示为工具并提供 1–3 次少量示例的工具演示以利用上下文学习。
- 通过从专家模型抽取前 k 个意见并将其作为参考注入到提示上下文中,引入 Additional Opinions。
- 在 WebShop 和 ALFWorld 上与模仿学习基线和各种大语言模型进行对比评估。
- 使用低温度以减少随机性,并在 IL+Auto-GPT 变体中进行多次运行以控制方差。
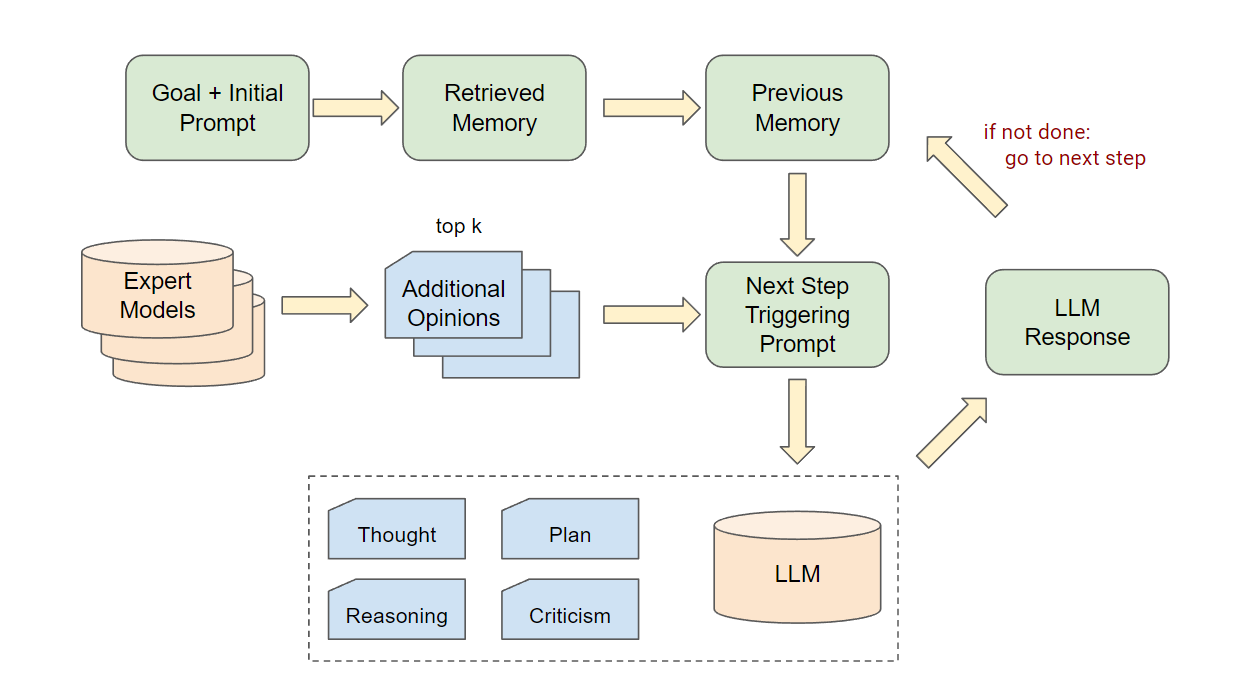
实验结果
研究问题
- RQ1 Auto-GPT 风格的代理是否可以有效适应类似真实世界环境的在线决策任务?
- RQ2哪些 LLM(GPT-4、GPT-3.5、Claude、Vicuna)在 WebShop 和 ALFWorld 的 Auto-GPT 配置中表现最好?
- RQ3在不微调基础 LLM 的情况下,结合外部专家模型的 Additional Opinions 是否能提升决策性能?
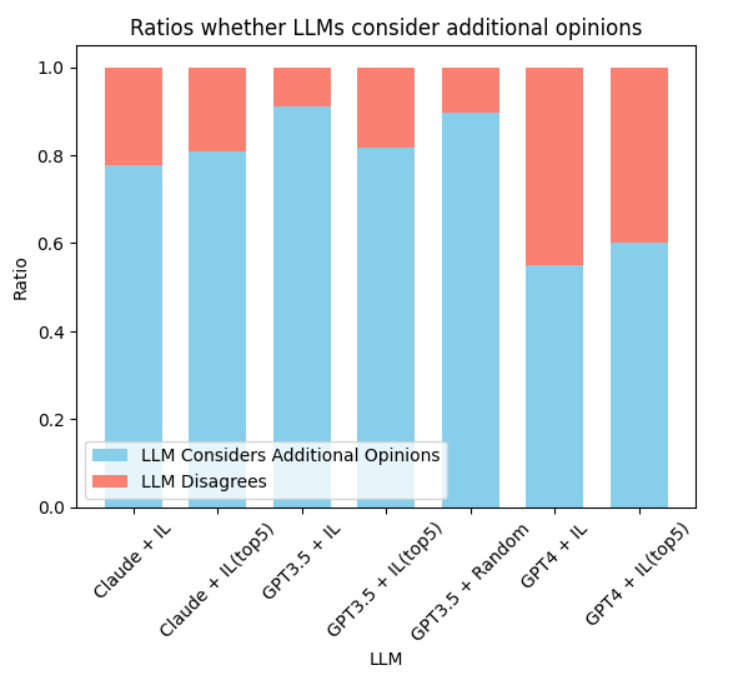
- RQ4单一与多重额外意见对性能的相对影响有多大,且在不同任务和模型下有何差异?
主要发现
| 模型 | 成功率 | 奖励 | 精度 | 购买率 | 模型 | 成功率 | 奖励 | 精度 | 完成率 |
|---|---|---|---|---|---|---|---|---|---|
| Rule | 0.060 | 44.589 | 0.060 | 1.000 | |||||
| IL w/o. Image | 0.213 | 56.056 | 0.213 | 1.000 | |||||
| IL | 0.227 | 57.689 | 0.227 | 1.000 | |||||
| Auto-GPT(Claude) | 0.140 | 47.617 | 0.146 | 0.960 | |||||
| Auto-GPT(Claude) + IL | 0.240 | 48.600 | 0.270 | 0.890 | |||||
| Auto-GPT(Claude) + IL(top5) | 0.220 | 52.010 | 0.229 | 0.960 | |||||
| Auto-GPT(GPT3.5) | 0.120 | 43.833 | 0.140 | 0.860 | |||||
| Auto-GPT(GPT3.5) + IL | 0.200 | 47.717 | 0.241 | 0.830 | |||||
| Auto-GPT(GPT3.5) + IL(top5) | 0.230 | 52.827 | 0.279 | 0.820 | |||||
| AutoGPT(GPT3.5) + Random | 0.060 | 22.333 | 0.136 | 0.440 | |||||
| Auto-GPT(GPT4) | 0.240 | 46.133 | 0.353 | 0.680 | |||||
| Auto-GPT(GPT4) + IL | 0.300 | 56.233 | 0.361 | 0.830 | |||||
| Auto-GPT(GPT4) + IL(top5) | 0.320 | 61.550 | 0.372 | 0.860 | |||||
| Auto-GPT(Vicuna) | 0.000 | 0.000 | 0.000 | 0.000 | |||||
| Auto-GPT(Vicuna) (duplicate) | 0.000 | 0.000 | 0.000 | 0.000 | |||||
| IL w/o. Beam Search | 0.179 | 24 | 1.000 | 0.179 | |||||
| IL | 0.306 | 41 | 1.000 | 0.441 | |||||
| Auto-GPT(Claude) | 0.082 | 11 | 0.104 | 0.791 | |||||
| Auto-GPT(Claude) + IL | 0.090 | 12 | 0.130 | 0.687 | |||||
| Auto-GPT(GPT3.5) | 0.075 | 10 | 0.078 | 0.866 | |||||
| Auto-GPT(GPT3.5) + IL | 0.030 | 4 | 0.048 | 0.470 | |||||
| Auto-GPT(GPT4) | 0.485 | 65 | 0.628 | 0.582 | |||||
| Auto-GPT(GPT4) + IL | 0.515 | 69 | 0.789 | 0.530 | |||||
| Auto-GPT(Vicuna) | 0.000 | 0 | 0.000 | 0.000 |
- 基于 GPT-4 的 Auto-GPT 变体在两个任务上均表现最佳。
- 从专家模型提供前 k 个 Additional Opinions 能提升性能,GPT-4 在多意见的情况下尤为受益。
- 在 WebShop 中,GPT-4 与 Additional Opinions 的组合在成功率、精度和奖励方面优于许多基线。
- 在 ALFWorld 中,GPT-4 显著超越模仿学习基线,且 IL 中的束搜索对结果有影响。
- Claude 与 GPT-3.5 在 Auto-GPT 设置下通常不如 GPT-4,但存在延迟权衡。
- 基于 Vicuna 的 Auto-GPT 在这些设置中表现较差或无法生成格式化响应。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。