[论文解读] AutoRT: Embodied Foundation Models for Large Scale Orchestration of Robotic Agents
AutoRT 系统使用视觉-语言模型和语言模型来协调整个现实世界机器人舰队进行多样化数据收集,在7 months内覆盖 20+ 台机器人实现 77k episodes。
Foundation models that incorporate language, vision, and more recently actions have revolutionized the ability to harness internet scale data to reason about useful tasks. However, one of the key challenges of training embodied foundation models is the lack of data grounded in the physical world. In this paper, we propose AutoRT, a system that leverages existing foundation models to scale up the deployment of operational robots in completely unseen scenarios with minimal human supervision. AutoRT leverages vision-language models (VLMs) for scene understanding and grounding, and further uses large language models (LLMs) for proposing diverse and novel instructions to be performed by a fleet of robots. Guiding data collection by tapping into the knowledge of foundation models enables AutoRT to effectively reason about autonomy tradeoffs and safety while significantly scaling up data collection for robot learning. We demonstrate AutoRT proposing instructions to over 20 robots across multiple buildings and collecting 77k real robot episodes via both teleoperation and autonomous robot policies. We experimentally show that such "in-the-wild" data collected by AutoRT is significantly more diverse, and that AutoRT's use of LLMs allows for instruction following data collection robots that can align to human preferences.
研究动机与目标
- 动机:证明需要在实验室环境之外进行大规模、现实世界的机器人数据收集。
- 提出一个系统,使用 foundation models 来为一支机器人舰队规划、落地并执行任务。
- 在安全约束下,允许由自主策略和人工远程操作员混合监督。
- 在多座建筑中进行真实世界部署并进行大量数据收集的演示。
- 证明通过 AutoRT 收集的数据可以提升下游机器人学习模型。
提出的方法
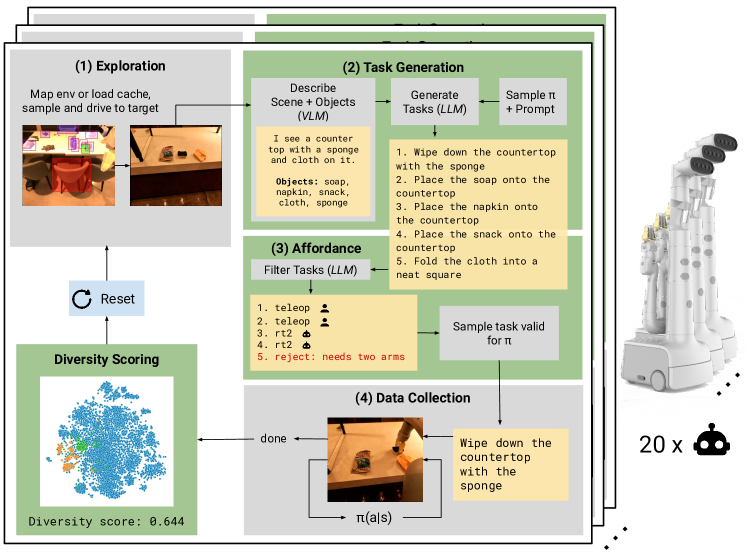
- 使用一个视觉-语言模型来描述场景并定位对象。
- 利用大型语言模型从场景描述中生成多样化、新颖的操作任务。
- 应用包含安全和具身性规则的机器人宪法来约束任务提案。
- 加入一个可供性筛选步骤,其中LLM评估并选择可行的任务与策略。
- 在监督约束下,使用多种采集策略(teleop、 scripted pick、 RT-2)来协调一支机器人舰队。
- 评估生成任务的多样性和可行性,并展示数据在 RT-1 模型微调中的效用。
实验结果
研究问题
- RQ1一个由具身基础模型驱动的系统能否在一支机器人舰队中扩展现实世界的机器人数据收集规模?
- RQ2LLMs 在基于视觉观测的前提下,生成安全、可行且多样化的操作任务的能力有多高?
- RQ3机器人宪法与可供性提示对任务安全性与相关性的影响是什么?
- RQ4AutoRT 数据对下游机器人学习模型(如 RT-1)的影响如何?
- RQ5在野外环境下进行混合监督数据收集的吞吐量、多样性与安全性特征是什么?
主要发现
| Collect Policy | #Episodes | Success Rate |
|---|---|---|
| Scripted Policy | 73293 | 21% |
| Teleop | 3060 | 82% |
| RT-2 | 936 | 4.7% |
- AutoRT 在 7 个月内,在 4 座建筑、53 台机器人上收集了 77,000 real-world episodes。
- 单个人类监督 3–5 台机器人,实现可扩展部署。
- 遥控操作获得最高的任务成功率(82%),而脚本化策略使用最频繁(73,293 episodes)。
- RT-2 自动化在收集阶段的成功率较低(4.7%),反映了训练数据的领域转移。
- AutoRT 数据比基线具有更高的语言和视觉多样性,且 prompts 数据可提升 RT-1 的性能(picking height、 wiping)。
- 宪法性提示和基于自我反思的可供性筛选提高了所提议任务的安全性与可行性。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。