[论文解读] Balancing Specialized and General Skills in LLMs: The Impact of Modern Tuning and Data Strategy
论文提出一个框架,通过在域内数据和通用数据之间保持平衡混合来微调大型语言模型,对功能相关任务进行45题评估,并分析模型规模和持续训练如何影响性能。
This paper introduces a multifaceted methodology for fine-tuning and evaluating large language models (LLMs) for specialized monetization tasks. The goal is to balance general language proficiency with domain-specific skills. The methodology has three main components: 1) Carefully blending in-domain and general-purpose data during fine-tuning to achieve an optimal balance between general and specialized capabilities; 2) Designing a comprehensive evaluation framework with 45 questions tailored to assess performance on functionally relevant dimensions like reliability, consistency, and business impact; 3) Analyzing how model size and continual training influence metrics to guide efficient resource allocation during fine-tuning. The paper details the design, data collection, analytical techniques, and results validating the proposed frameworks. It aims to provide businesses and researchers with actionable insights on effectively adapting LLMs for specialized contexts. We also intend to make public the comprehensive evaluation framework, which includes the 45 tailored questions and their respective scoring guidelines, to foster transparency and collaboration in adapting LLMs for specialized tasks.
研究动机与目标
- 解决在专注于变现的 LLM 中平衡通用语言技能与领域专用能力的挑战。
- 提出在监督微调过程中混合域内数据和通用数据的数据平衡策略。
- 开发一个包含 45 个问题的综合评估框架,用于评估可靠性、一致性和商业影响。
- 分析模型规模和持续训练如何影响性能,以指导高效资源分配。
提出的方法
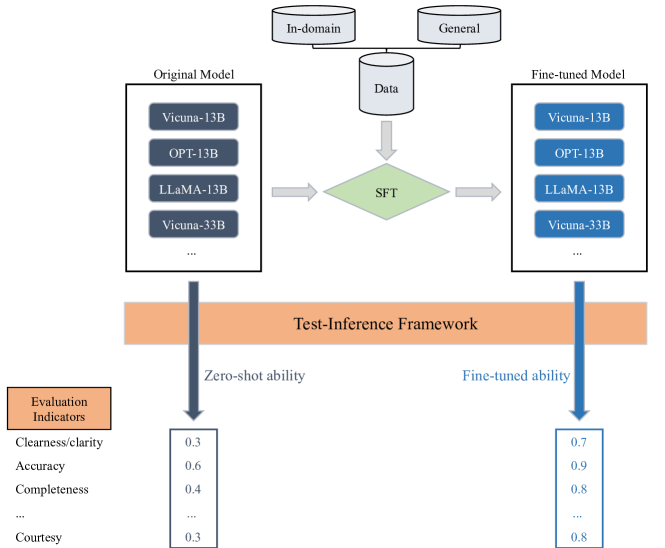
- 在监督微调过程中结合域内数据和通用数据的数 据集混合技术,以在提升领域技能的同时保持通用能力。
- 监督微调配置包括余弦学习率调度、0.1 的权重衰减、2048 token 序列长度,以及与模型规模相关的批量大小。
- 一个测试-推断模块,使用覆盖一般任务和域内任务的精心挑选的 45 个问题进行全面评估。
- 一个八类、动态加权的评分框架,用于评估回答在清晰度、准确性、完整性、安全性、具体性、考虑性、礼貌性和总体表现方面的表现。
- 持续训练实验(1–5 个 epoch)以研究对性能的影响,并提供一个开源评估框架以提高透明度。
- 数据隐私措施以及从公开来源和产品/服务数据中进行数据融合,以创建平衡的训练语料。
实验结果
研究问题
- RQ1如何将域内的变现数据与通用域数据混合,以在保持通用语言技能的同时提升领域特定能力?
- RQ2模型规模和持续训练对专项 LLM 的评估指标有何影响?
- RQ3与标准基准相比,45 问题评估框架是否能更准确地评估商业影响?
- RQ4数据平衡策略如何影响在变现场景中的可靠性、一致性以及可执行的商业结果?
主要发现
| 模型 | 清晰度 | 准确性 | 完整性 | 简明性 | 安全性 | 具体性 | 考虑 | 礼貌 | 总体评分 |
|---|---|---|---|---|---|---|---|---|---|
| Vicuna-13b-v1.1 | 0.785 | 0.707 | 0.781 | 0.911 | 0.820 | 0.726 | 1.00 | 0.922 | 0.820 |
| Vicuna-13b-v1.3 | 0.915 | 0.644 | 0.633 | 0.952 | 1.00 | 0.926 | 0.989 | 1.00 | 0.828 |
| Llama-2-13b | 0.904 | 0.763 | 0.663 | 0.967 | 0.967 | 0.867 | 1.00 | 1.00 | 0.856 |
| Vicuna-33b-v1.3 | 0.937 | 0.718 | 0.730 | 0.970 | 1.00 | 1.00 | 1.00 | 1.00 | 0.869 |
- 将域内数据与域外数据混合有助于在提升专业化效用的同时保持通用能力。
- 全面的 45 问题评估框架比标准基准更好地捕捉商业影响。
- 持续训练和模型扩展以细微方式影响评估指标,为资源分配提供指导。
- 较大规模的模型通常具有更强的能力,取决于 epoch 和模型变体,在简洁性和完整性之间存在权衡。
- Vicuna-13b-v1.3 在某些标准上通常优于 v1.1,而 Llama-2-13b 和 Vicuna-33b-v1.3 在各类别上显示出不同的优势。
- 研究提供了一个基准,显示多个 SFT 训练模型的八类别分数和总体表现。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。