[论文解读] Be Your Own Prada: Fashion Synthesis with Structural Coherence
本文提出了一种两阶段 GAN 框架,用于文本条件下的时尚生成,能够在保留穿着者体型和姿态的同时生成连贯且区域特定的服装纹理。通过首先在空间约束下生成语义分割图,然后使用组合映射层渲染纹理,该方法在结构连贯性和视觉质量方面优于基线模型,经定量指标和用户研究验证,平均排名为 1.544。
We present a novel and effective approach for generating new clothing on a wearer through generative adversarial learning. Given an input image of a person and a sentence describing a different outfit, our model "redresses" the person as desired, while at the same time keeping the wearer and her/his pose unchanged. Generating new outfits with precise regions conforming to a language description while retaining wearer's body structure is a new challenging task. Existing generative adversarial networks are not ideal in ensuring global coherence of structure given both the input photograph and language description as conditions. We address this challenge by decomposing the complex generative process into two conditional stages. In the first stage, we generate a plausible semantic segmentation map that obeys the wearer's pose as a latent spatial arrangement. An effective spatial constraint is formulated to guide the generation of this semantic segmentation map. In the second stage, a generative model with a newly proposed compositional mapping layer is used to render the final image with precise regions and textures conditioned on this map. We extended the DeepFashion dataset [8] by collecting sentence descriptions for 79K images. We demonstrate the effectiveness of our approach through both quantitative and qualitative evaluations. A user study is also conducted. The codes and the data are available at http://mmlab.ie.cuhk. edu.hk/projects/FashionGAN/.
研究动机与目标
- 在保留穿着者体型和姿态的前提下,实现基于单张输入图像和自然语言描述的新服装生成。
- 解决在同时依赖输入图像和自然语言描述时,时尚生成中的结构连贯性挑战。
- 克服标准 GAN 在图像生成过程中维持全局结构并避免模糊伪影的局限性。
- 开发一种能够幻化缺失身体部位(如手臂)但确保身体区域一致可见的方法。
- 通过定量指标和关于分割真实性和图像质量的用户研究,评估模型性能。
提出的方法
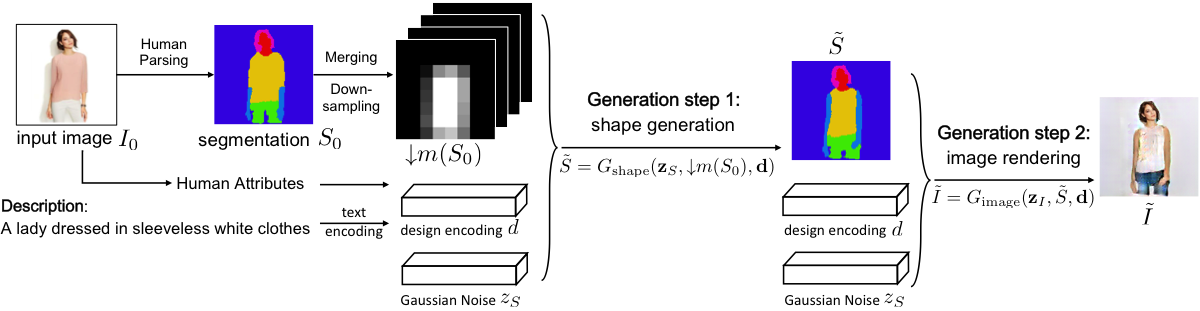
- 该方法采用两阶段 GAN:首先基于输入图像和文本生成语义分割图,然后从该图和文本生成最终图像。
- 基于输入图像提出一种新颖的空间约束,以引导第一阶段 GAN 在不与文本描述冲突的前提下保留穿着者的姿态和身体结构。
- 第二阶段生成器采用一种新型组合映射层,实现区域特定的纹理合成,相比非组合 GAN,显著提升了连贯性并减少了模糊。
- 模型在扩展版 DeepFashion 数据集上进行训练,包含 79,000 幅上半身图像,附带句子描述和人体部位标签。
- 第一阶段 GAN 生成的分割图定义了身体部位和服装的区域,确保与输入图像的结构一致性。
- 第二阶段 GAN 利用分割图和文本嵌入生成具有精确纹理和身体部位一致可见性的照片级真实感图像。

实验结果
研究问题
- RQ1两阶段 GAN 框架能否在仅使用单张输入图像和文本描述的情况下,生成具有高度结构连贯性的时尚图像,同时保留穿着者的体型和姿态?
- RQ2从输入图像导出的空间约束在引导生成合理分割图方面有多有效,且不会与文本描述冲突?
- RQ3与非组合 GAN 相比,组合映射层在时尚生成中提升区域特定纹理渲染的程度如何?
- RQ4与基线模型相比,人类参与者对生成分割图的真实感和最终图像的视觉质量感知如何?
- RQ5当在具有纯色背景的数据集上进行训练时,该模型能否泛化到未见过的服装和背景类型?
主要发现
- 在用户研究中,所提方法的平均用户排名为 1.544,显著优于所有基线模型,包括 2D 非参数方法(平均排名 2.286)。
- 模型生成的分割图使 42% 的参与者误判为真实图像,表明中间输出具有高度的真实感和合理性。
- 组合映射层有效减少了模糊,并提升了区域特定纹理的一致性,与非组合基线的定性对比结果清晰显示了这一点。
- 结合空间约束的两阶段框架显著减少了伪影并提升了结构连贯性,尤其在需要幻化缺失身体部位的情况下表现更优。
- 用户排名和定性结果均表明,该模型在视觉质量和形状一致性方面优于单阶段 GAN 基线模型(如 One-Step-8-7 和 One-Step-8-4)。
- 当在包含纹理背景的数据上进行训练时,模型能泛化到此类背景,因为潜在向量捕捉了背景分布,而无需显式建模背景。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。