[论文解读] Benchmarking Large Language Models for News Summarization
本文对十个大型语言模型在新闻摘要任务中进行了全面的人类评估,发现指令微调对零-shot性能的影响大于模型规模,并显示高质量的自由撰稿摘要揭示了基于参考的指标的局限性。
Large language models (LLMs) have shown promise for automatic summarization but the reasons behind their successes are poorly understood. By conducting a human evaluation on ten LLMs across different pretraining methods, prompts, and model scales, we make two important observations. First, we find instruction tuning, and not model size, is the key to the LLM's zero-shot summarization capability. Second, existing studies have been limited by low-quality references, leading to underestimates of human performance and lower few-shot and finetuning performance. To better evaluate LLMs, we perform human evaluation over high-quality summaries we collect from freelance writers. Despite major stylistic differences such as the amount of paraphrasing, we find that LMM summaries are judged to be on par with human written summaries.
研究动机与目标
- 找出促成LLMs零-shot新闻摘要性能的设计决策。
- 评估模型规模、提示和指令微调如何影响摘要质量。
- 评估基于参考的常规度量在LLM摘要中的可靠性。
- 将LLM输出与自由职业者撰写的高质量人工摘要进行比较。
- 提供高质量的评估数据及未来基准测试资源。
提出的方法
- 对CNN/Daily Mail和XSUM数据集进行系统的人类评估,覆盖十种不同的LLM。
- 使用三项评注标准:可信度(二元)、连贯性(1–5)、相关性(1–5)。
- 比较零-shot与少样本提示,并包含微调基线(Pegasus、BRIO)。
- 通过Upwork招募高质量自由职业摘要,以评估人类水平表现与度量可靠性。
- 通过“剪切-粘贴”操作分类法分析摘取式与改写式风格。
- 发布18种模型设定和两个数据集的评估数据。
实验结果
研究问题
- RQ1指令微调的LLMs在零-shot新闻摘要任务中是否优于以规模为主、未进行指令微调的模型?
- RQ2高质量人工参考对LLM和微调模型的感知性能与实际性能有何影响?
- RQ3基于参考的自动指标在评估CNN/Daily Mail与XSUM的高质量LLM输出时是否可靠?
- RQ4LLM摘要在忠实度、连贯性和信息性方面与自由职业者人工摘要相比如何?
主要发现
| Model | Faithfulness CNN/DM | Coherence CNN/DM | Relevance CNN/DM | Faithfulness XSUM | Coherence XSUM | Relevance XSUM |
|---|---|---|---|---|---|---|
| GPT-3 (350M) | 0.29 | 1.92 | 1.84 | 0.26 | 2.03 | 1.90 |
| GPT-3 (6.7B) | 0.29 | 1.77 | 1.93 | 0.77 | 3.16 | 3.39 |
| GPT-3 (175B) | 0.76 | 2.65 | 3.50 | 0.80 | 2.78 | 3.52 |
| Ada Instruct v1 (350M*) | 0.88 | 4.02 | 4.26 | 0.81 | 3.90 | 3.87 |
| Curie Instruct v1 (6.7B*) | 0.97 | 4.24 | 4.59 | 0.96 | 4.27 | 4.34 |
| Davinci Instruct v2 (175B*) | 0.99 | 4.15 | 4.60 | 0.97 | 4.41 | 4.28 |
| Anthropic-LM (52B) Five-shot | 0.94 | 3.88 | 4.33 | 0.70 | 4.77 | 4.14 |
| Cohere XL (52.4B) | 0.99 | 3.42 | 4.48 | 0.63 | 4.79 | 4.00 |
| GLM (130B) | 0.94 | 3.69 | 4.24 | 0.74 | 4.72 | 4.12 |
| OPT (175B) | 0.96 | 3.64 | 4.33 | 0.67 | 4.80 | 4.01 |
| GPT-3 (350M) – (repeat) | 0.86 | 3.73 | 3.85 | - | - | - |
| GPT-3 (6.7B) – (repeat) | 0.97 | 3.87 | 4.17 | 0.75 | 4.19 | 3.36 |
| GPT-3 (175B) – (repeat) | 0.99 | 3.95 | 4.34 | 0.69 | 4.69 | 4.03 |
| Ada Instruct v1 (350M*) – (repeat) | 0.84 | 3.84 | 4.07 | 0.63 | 3.54 | 3.07 |
| Curie Instruct v1 (6.7B*) – (repeat) | 0.96 | 4.30 | 4.43 | 0.85 | 4.28 | 3.80 |
| Davinci Instruct (175B*) – (repeat) | 0.98 | 4.13 | 4.49 | 0.77 | 4.83 | 4.33 |
| Brio (Fine-tuned) | 0.94 | 3.94 | 4.40 | 0.58 | 4.68 | 3.89 |
| Pegasus (Fine-tuned) | 0.97 | 3.93 | 4.38 | 0.57 | 4.73 | 3.85 |
| Existing references | 0.84 | 3.20 | 3.94 | 0.37 | 4.13 | 3.00 |
- 指令微调,而非模型规模,是跨数据集零-shot摘要性能的关键驱动因素。
- 最大模型(如175B)在连贯性和相关性方面可能被较小的指令微调模型超越。
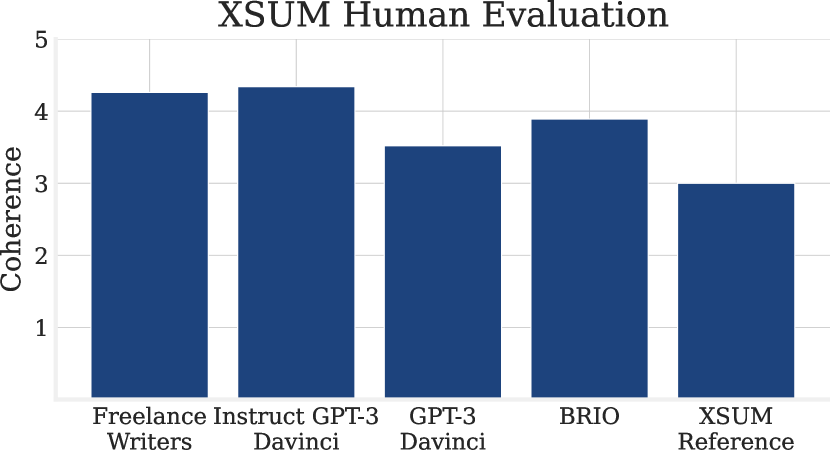
- 人类对XSUM中的参考摘要评估低于最佳LLM输出,质疑对这类参考的依赖。
- 自由职业作者产出比CNN/DM和XSUM基线更高质量的参考;Instruct Davinci通常与自由职业者相当。
- 使用更高质量的参考时,XSUM上Rouge-L与人类忠实性的相关性提高。
- 注释者在LLM与自由职业者摘要偏好上存在显著差异,表明风格具有主观性。

更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。