[论文解读] Beyond the Safeguards: Exploring the Security Risks of ChatGPT
本论文综述了 ChatGPT 的安全风险,实证测试内容过滤器,并讨论了绕过技术与大模型安全与伦理的缓解策略。
The increasing popularity of large language models (LLMs) such as ChatGPT has led to growing concerns about their safety, security risks, and ethical implications. This paper aims to provide an overview of the different types of security risks associated with ChatGPT, including malicious text and code generation, private data disclosure, fraudulent services, information gathering, and producing unethical content. We present an empirical study examining the effectiveness of ChatGPT's content filters and explore potential ways to bypass these safeguards, demonstrating the ethical implications and security risks that persist in LLMs even when protections are in place. Based on a qualitative analysis of the security implications, we discuss potential strategies to mitigate these risks and inform researchers, policymakers, and industry professionals about the complex security challenges posed by LLMs like ChatGPT. This study contributes to the ongoing discussion on the ethical and security implications of LLMs, underscoring the need for continued research in this area.
研究动机与目标
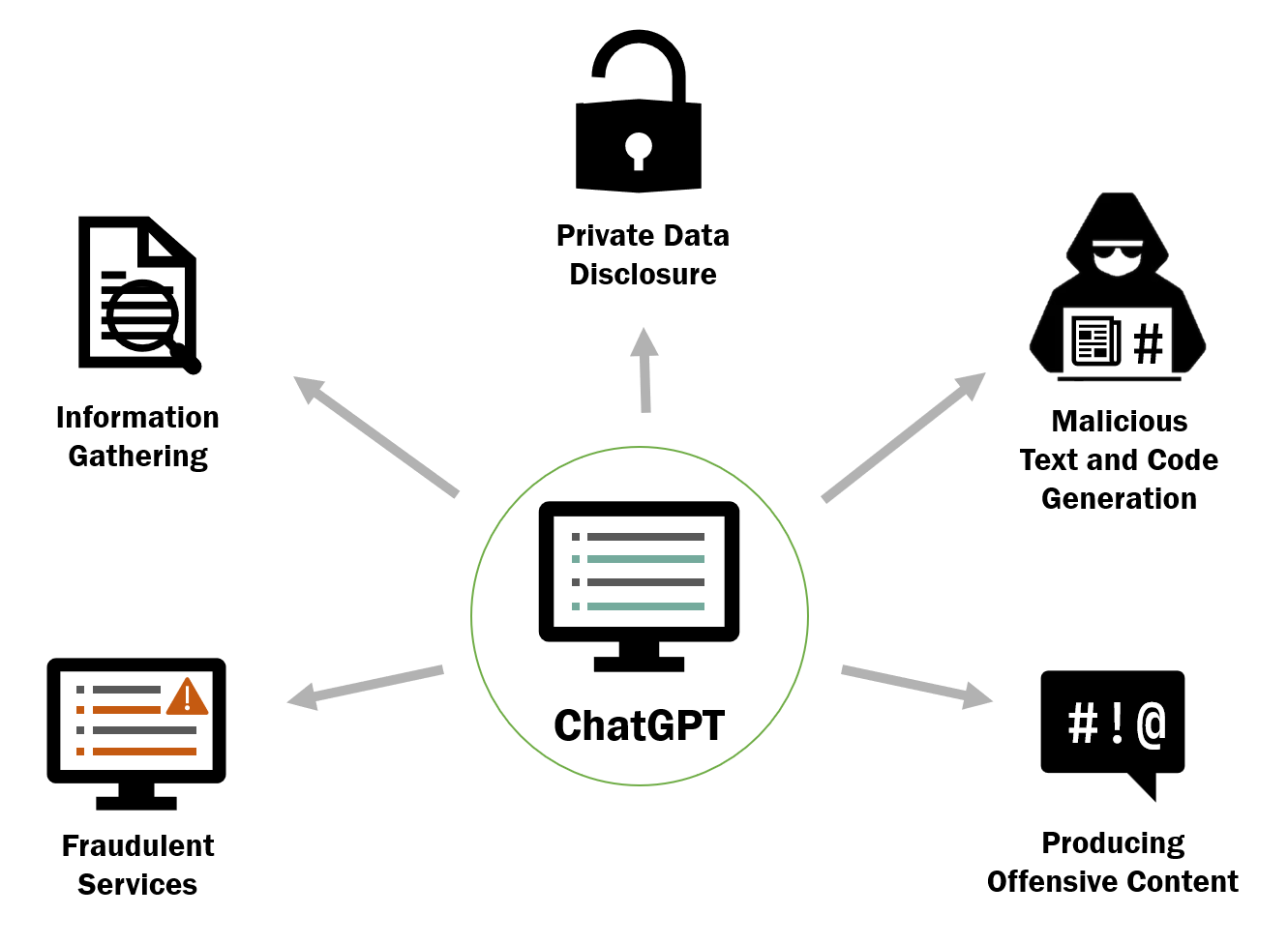
- 概述与 ChatGPT 及相关大语言模型相关的安全风险。
- 实证评估 ChatGPT 内容过滤器的有效性及其被绕过的方式。
- 分析所识别风险的伦理影响和潜在后果。
- 提出缓解策略,为研究人员、决策者和行业提供参考。
- 强调空缺并指导未来在大语言模型安全方面的研究。
提出的方法
- 基于文献与实验的安全性影响的定性分析。
- 通过精心设计的提示和角色扮演对绕过 ChatGPT 内容过滤器进行实证演示。
- 展示真实的交互示例(信息收集、类似钓鱼的邮件、代码生成、个人数据披露、不道德内容)。
- 讨论 RLHF 与微调作为防护措施及其局限性。
- 提出缓解策略,如高级内容过滤、数据标注和输出扫描。
实验结果
研究问题
- RQ1与 ChatGPT 相关的哪些安全风险,以及它们在实践中的表现形式?
- RQ2ChatGPT 的内容过滤器有多有效,且可通过哪些方法被绕过?
- RQ3这些安全风险对用户和社会会带来哪些伦理影响与潜在后果?
- RQ4哪些缓解策略可以在保留模型效用的同时降低这些风险?
主要发现
- ChatGPT 的内容过滤器并非万无一失,能够通过创造性指令遵循与角色扮演来绕过。
- 恶意使用包括信息收集、类似钓鱼的文本生成、恶意代码生成、个人数据披露、欺诈性服务以及生成不道德内容。
- RLHF 与微调提升了安全性,但并不能完全消除风险,且绕过技术在 GPT-3.5 与 GPT-4 的环境中持续存在。
- 存在显著的隐私担忧,如成员身份推断风险和个人信息可能泄露。
- 讨论的缓解策略包括高级内容过滤、数据标注、输出扫描,以及利用人工智能来过滤人工智能输出。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。