[论文解读] BioMedLM: A 2.7B Parameter Language Model Trained On Biomedical Text
BioMedLM 是一个2.7B参数的GPT风格模型,仅在PubMed的摘要和文章上进行训练,在微调后实现了具有竞争力的生物医学问答性能,同时支持设备端推理和开放数据来源。
Models such as GPT-4 and Med-PaLM 2 have demonstrated impressive performance on a wide variety of biomedical NLP tasks. However, these models have hundreds of billions of parameters, are computationally expensive to run, require users to send their input data over the internet, and are trained on unknown data sources. Can smaller, more targeted models compete? To address this question, we build and release BioMedLM, a 2.7 billion parameter GPT-style autoregressive model trained exclusively on PubMed abstracts and full articles. When fine-tuned, BioMedLM can produce strong multiple-choice biomedical question-answering results competitive with much larger models, such as achieving a score of 57.3% on MedMCQA (dev) and 69.0% on the MMLU Medical Genetics exam. BioMedLM can also be fine-tuned to produce useful answers to patient questions on medical topics. This demonstrates that smaller models can potentially serve as transparent, privacy-preserving, economical and environmentally friendly foundations for particular NLP applications, such as in biomedicine. The model is available on the Hugging Face Hub: https://huggingface.co/stanford-crfm/BioMedLM.
研究动机与目标
- Motivate the development of a domain-specific, smaller LLM to address privacy, cost, and transparency concerns of large models in biomedicine.
提出的方法
- Autoregressive decoder-only Transformer (GPT-2 style) with 2.7B parameters.
- Domain-specific Byte-Pair Encoding tokenizer trained on PubMed abstracts to improve tokenization of biomedical terms.
- Pre-training on PubMed abstracts and articles (34.6B tokens; 8.67 passes; ~300B tokens explored) using mixed-precision, bf16 for final training, and Decoupled AdamW optimizer.
- Fine-tuning for downstream biomedical QA tasks with architecture specialized for multiple-choice prompts (per-task prompt shaping and a final linear classifier over answer scores).
- Generation-style fine-tuning for consumer-health question answering (long-form responses) using web-derived QA pairs.

实验结果
研究问题
- RQ1Can a compact, domain-specialized model (2.7B parameters) match or approach the performance of larger models on biomedical QA tasks?
- RQ2Does training exclusively on PubMed data and using a biomedical tokenizer improve downstream task performance relative to general-domain baselines?
- RQ3What are the trade-offs in privacy, cost, and accessibility when deploying a small, open biomedical LLM compared to closed, large models?
主要发现
| 数据集 | 模型 | 参数 | 方法 | 准确率 |
|---|---|---|---|---|
| MedMCQA | GPT-4 | – | few-shot | 72.4 |
| MedMCQA | Flan-PaLM | 540B | few-shot | 57.6 |
| MedMCQA | BioMedLM | 2.7B | fine-tune | 57.3 |
| MedMCQA | Galactica | 120B | zero-shot | 52.9 |
| MedMCQA | GPT-3.5 | 175B | few-shot | 51.0 |
| MedQA | Med-PaLM 2 | – | closed, few-shot | 85.4 |
| MedQA | GPT-4 | – | closed, few-shot | 81.4 |
| MedQA | Flan-PaLM | 540B | closed, few-shot | 67.2 |
| MedQA | BioMedLM (MedMCQA data + classifier) | 2.7B | fully open, fine-tune | 54.7 |
| MedQA | GPT-3.5 | 175B | closed, few-shot | 53.6 |
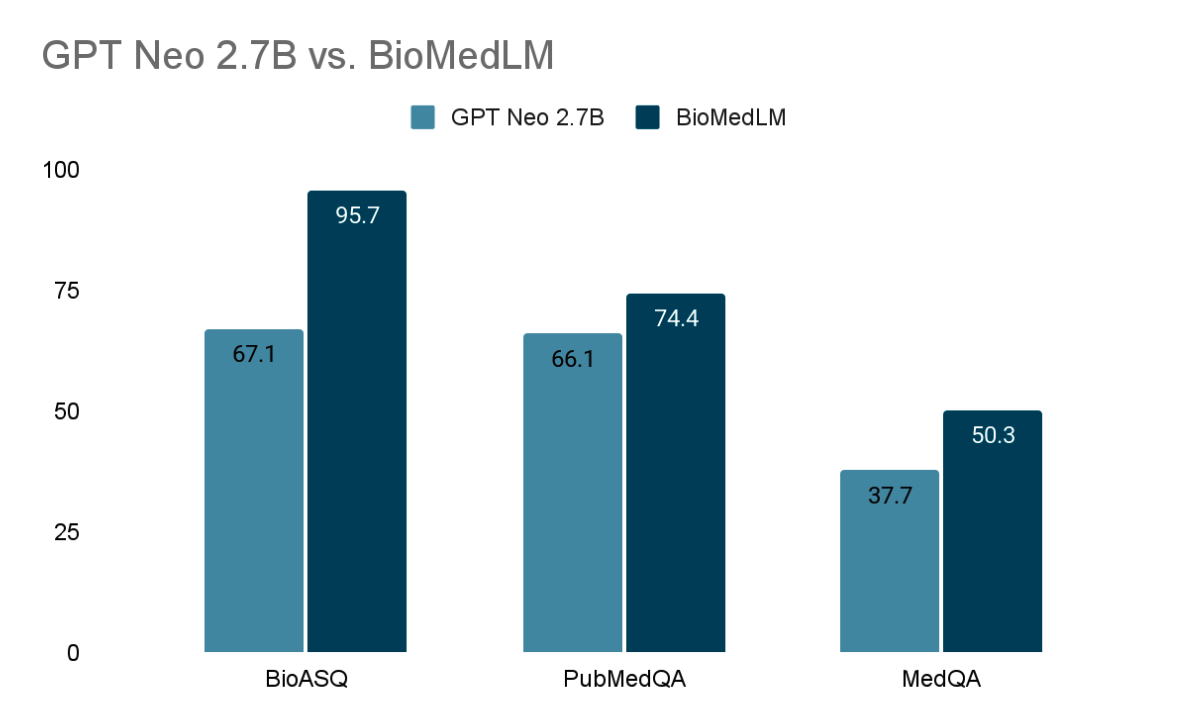
| MedQA | BioMedLM (classifier) | 2.7B | fully open, fine-tune | 50.3 |
| MedQA | DRAGON | 360M | fully open, fine-tune | 47.5 |
| MedQA | BioLinkBERT | 340M | fully open, fine-tune | 45.1 |
| MedQA | Galactica | 120B | open weights, zero-shot | 44.4 |
| MedQA | GPT-Neo 2.7B | 2.7B | fully open, fine-tune | 37.7 |
| BioASQ | BioMedLM | 2.7B | fine-tune | 95.7 |
| BioASQ | DRAGON | 360M | fine-tune | 96.4 |
| BioASQ | BioLinkBERT | 340M | fine-tune | 94.9 |
| BioASQ | Galactica | 120B | zero-shot | 94.3 |
| BioASQ | GPT-Neo 2.7B | 2.7B | fine-tune | 67.1 |
| PubMedQA | BioMedLM | 2.7B | fine-tune | 74.4 |
- BioMedLM achieves competitive results on multiple biomedical QA benchmarks after fine-tuning, approaching or matching larger models in several tasks (e.g., MedMCQA 57.3%, MMLU Medical Genetics 69.0%).
- Domain-specific pre-training on PubMed with a specialized tokenizer yields noticeable gains over GPT-2/tokenizer baselines (e.g., MedQA improvement from 33.05 to 34.98 at 125M scale).
- Compared to GPT-Neo 2.7B trained on general English data, BioMedLM substantially outperforms on select QA tasks (e.g., 27 percentage point improvement on BioASQ).
- BioMedLM supports on-device inference and can be fine-tuned on modest hardware while providing transparency about training data and architecture.
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。