[论文解读] BOLAA: Benchmarking and Orchestrating LLM-augmented Autonomous Agents
BOLAA 基准测试不同 LAA 架构与多种 LLM 主干,并引入一个多智能体控制器来协调专门的 LAAs,在决策与知识推理任务上进行评估。
The massive successes of large language models (LLMs) encourage the emerging exploration of LLM-augmented Autonomous Agents (LAAs). An LAA is able to generate actions with its core LLM and interact with environments, which facilitates the ability to resolve complex tasks by conditioning on past interactions such as observations and actions. Since the investigation of LAA is still very recent, limited explorations are available. Therefore, we provide a comprehensive comparison of LAA in terms of both agent architectures and LLM backbones. Additionally, we propose a new strategy to orchestrate multiple LAAs such that each labor LAA focuses on one type of action, extit{i.e.} BOLAA, where a controller manages the communication among multiple agents. We conduct simulations on both decision-making and multi-step reasoning environments, which comprehensively justify the capacity of LAAs. Our performance results provide quantitative suggestions for designing LAA architectures and the optimal choice of LLMs, as well as the compatibility of both. We release our implementation code of LAAs to the public at \url{https://github.com/salesforce/BOLAA}.
研究动机与目标
- 评估 LAA 架构在多种 LLM 主干上的表现。
- 识别架构与 LLM 的哪些组合能带来最佳任务性能。
- 研究通过控制器编排多个专门的 LAAs 的好处。
- 就可扩展的 LAA 系统的体系结构设计选择提供指南。
- 发布开源实现以促进可复现性。
提出的方法
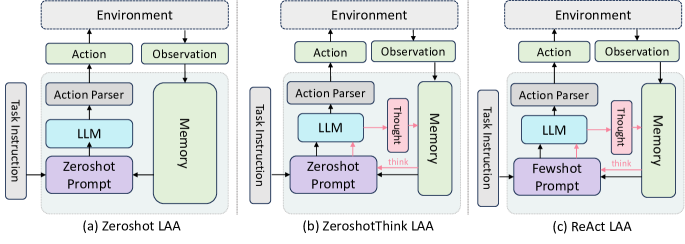
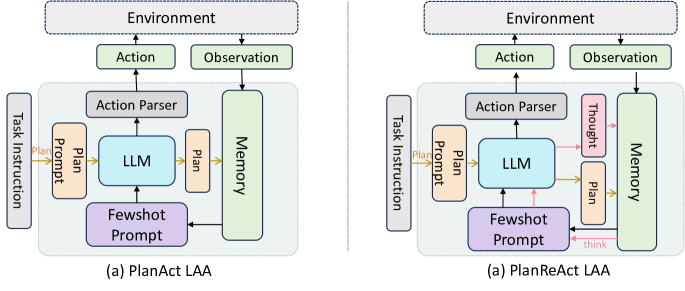
- 构建一套包含提示、自我思考和规划变体的6种单独 LAA 架构。
- 将架构与多种主干 LLM 配对,构成广泛的评估矩阵。
- 提出 BOLAA:一种基于控制器的架构,将行动路由到专门的劳务 LAAs(如分离的点击与搜索代理)。
- 在 WebShop(网页导航)和 HotPotQA(多跳知识推理)环境中评估。
- 报告最终奖励和中间 recalls 以评估有效性和通信质量。
实验结果
研究问题
- RQ1不同 LAA 架构在多样的 LLM 主干上,在网页导航和推理任务中的表现如何?
- RQ2通过控制器(BOLAA)编排多个专门的 LAAs 相对于单独代理是否能提升性能?
- RQ3上下文长度和模型规模对跨架构的 LAA 效能有何影响?
- RQ4哪些 LLM 主干和架构最能泛化到开放域任务与规划场景?
主要发现
| LLM | Len. | LAA 架构 | ZS | ZST | ReAct | PlanAct | PlanReAct | BOLAA |
|---|---|---|---|---|---|---|---|---|
| fastchat-t5-3b | 2k | 0.3971 | 0.2832 | 0.3098 | 0.3837 | 0.1507 | 0.5169 | |
| vicuna-7b | 2k | 0.0012 | 0.0002 | 0.1033 | 0.0555 | 0.0674 | 0.0604 | |
| vicuna-13b | 2k | 0.0340 | 0.0451 | 0.1509 | 0.3120 | 0.4127 | 0.5350 | |
| vicuna-33b | 2k | 0.1356 | 0.2049 | 0.1887 | 0.3692 | 0.3125 | 0.5612 | |
| llama-2-7b | 4k | 0.0042 | 0.0068 | 0.1248 | 0.3156 | 0.2761 | 0.4648 | |
| llama-2-13b | 4k | 0.0662 | 0.0420 | 0.2568 | 0.4892 | 0.4091 | 0.3716 | |
| llama-2-70b | 4k | 0.0122 | 0.0080 | 0.4426 | 0.2979 | 0.3770 | 0.5040 | |
| mpt-7b-instruct | 8k | 0.0001 | 0.0001 | 0.0573 | 0.0656 | 0.1574 | 0.0632 | |
| mpt-30b-instruct | 8k | 0.1664 | 0.1255 | 0.3119 | 0.3060 | 0.3198 | 0.4381 | |
| xgen-8k-7b-instruct | 8k | 0.0001 | 0.0015 | 0.0685 | 0.1574 | 0.1004 | 0.3697 | |
| longchat-7b-16k | 16k | 0.0165 | 0.0171 | 0.0690 | 0.0917 | 0.1322 | 0.1964 | |
| longchat-13b-16k | 16k | 0.0007 | 0.0007 | 0.2373 | 0.3978 | 0.4019 | 0.3205 | |
| text-davinci-003 | 4k | 0.5292 | 0.5395 | 0.5474 | 0.4751 | 0.4912 | 0.6341 | |
| gpt-3.5-turbo | 4k | 0.5061 | 0.5057 | 0.5383 | 0.4667 | 0.5483 | 0.6567 | |
| gpt-3.5-turbo-16k | 16k | 0.5657 | 0.5642 | 0.4898 | 0.4565 | 0.5607 | 0.6541 |
- BOLAA 在所测试的所有 LLM 上普遍获得最高奖励,表明专门化、协同代理的优势。
- LLM 与架构的最佳配对依任务与模型而定(例如 PlanAct、PlanReAct 或 BOLAA 在不同模型上表现不同)。
- 更大、能力更强的 LLM 往往优于较小模型,但极长的上下文可能导致更多幻觉,并不总是提升结果。
- 计划流程通常有利于开源 LLM,而某些知识推理任务中规划可能由于先前计划不一致而产生阻碍。
- 在 WebShop 中,结合专门劳动 LAAs(搜索和点击)的 BOLAA 持续产生强劲的表现和回忆;在 HotPotQA 中,基于 ReAct 的架构在少量示例提示下表现出色。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。