[论文解读] Brain in a Vat: On Missing Pieces Towards Artificial General Intelligence in Large Language Models
本文批评当前的 LLM 评估,认为它们夸大了能力,并概述实现真正通用人工智能所缺失的要素,强调通过现实世界互动与试错学习实现知行合一。
In this perspective paper, we first comprehensively review existing evaluations of Large Language Models (LLMs) using both standardized tests and ability-oriented benchmarks. We pinpoint several problems with current evaluation methods that tend to overstate the capabilities of LLMs. We then articulate what artificial general intelligence should encompass beyond the capabilities of LLMs. We propose four characteristics of generally intelligent agents: 1) they can perform unlimited tasks; 2) they can generate new tasks within a context; 3) they operate based on a value system that underpins task generation; and 4) they have a world model reflecting reality, which shapes their interaction with the world. Building on this viewpoint, we highlight the missing pieces in artificial general intelligence, that is, the unity of knowing and acting. We argue that active engagement with objects in the real world delivers more robust signals for forming conceptual representations. Additionally, knowledge acquisition isn't solely reliant on passive input but requires repeated trials and errors. We conclude by outlining promising future research directions in the field of artificial general intelligence.
研究动机与目标
- 评审现有的标准化评估和以能力为导向的 LLM 评估,并识别对 LLM 能力的高估。
- 提出一个框架,界定人工通用智能应涵盖的内容,超越 LLM。
- 突出指向 AGI 的缺失环节,聚焦于行动、世界锚定,以及经验性知识获取。
提出的方法
- 对用于评估 LLM 的标准化测试和以能力为导向的基准进行系统性评述。
- 对符号锚定、世界互动和知识获取的研究发现进行批判性综合。
- 对四个通用智能代理特征进行概念框架化。
- 讨论挑战 LLM 作为 AGI 的实证证据并勾勒未来研究方向。
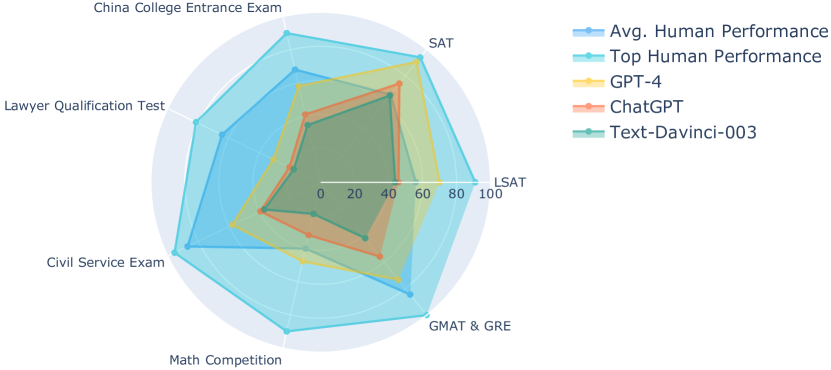
实验结果
研究问题
- RQ1当前 LLM 评估方法在捕捉通用智能方面的局限性是什么?
- RQ2除了 LLM 展示的能力之外,人工通用智能还应具备哪些要素?
- RQ3将知识与行动统一起来的 AI 系统还缺少哪些关键环节?
主要发现
- LLMs 在语言类测试中表现出色,但在训练数据较少的学科领域的推理与问题解决方面存在困难。
- 评估方法可能因数据偏差和评估指标选择而高估 LLM 的能力。
- 来自多个领域的证据表明 LLM 依赖捷径,缺乏稳健的符号理解,在分布外的因果与抽象推理任务中表现不佳。
- 符号锚定与现实世界互动被认为是实现健壮概念表征和泛化的关键。
- 作者主张未来的 AGI 方向应整合主动的世界参与、试错学习和有据可依的知识获取。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。