[论文解读] Can ChatGPT Write a Good Boolean Query for Systematic Review Literature Search?
该研究评估 ChatGPT 在为系统综述制定和改进布尔查询方面的能力,发现高精准度但召回率较低,提示词和示例质量显著影响性能;多步骤引导提示提高结果,带有 HQE 示例的提示最有帮助。
Systematic reviews are comprehensive reviews of the literature for a highly focused research question. These reviews are often treated as the highest form of evidence in evidence-based medicine, and are the key strategy to answer research questions in the medical field. To create a high-quality systematic review, complex Boolean queries are often constructed to retrieve studies for the review topic. However, it often takes a long time for systematic review researchers to construct a high quality systematic review Boolean query, and often the resulting queries are far from effective. Poor queries may lead to biased or invalid reviews, because they missed to retrieve key evidence, or to extensive increase in review costs, because they retrieved too many irrelevant studies. Recent advances in Transformer-based generative models have shown great potential to effectively follow instructions from users and generate answers based on the instructions being made. In this paper, we investigate the effectiveness of the latest of such models, ChatGPT, in generating effective Boolean queries for systematic review literature search. Through a number of extensive experiments on standard test collections for the task, we find that ChatGPT is capable of generating queries that lead to high search precision, although trading-off this for recall. Overall, our study demonstrates the potential of ChatGPT in generating effective Boolean queries for systematic review literature search. The ability of ChatGPT to follow complex instructions and generate queries with high precision makes it a valuable tool for researchers conducting systematic reviews, particularly for rapid reviews where time is a constraint and often trading-off higher precision for lower recall is acceptable.
研究动机与目标
- 评估 ChatGPT 是否能生成高质量的系统综述布尔查询。
- 将 ChatGPT 生成的查询与最先进的自动查询方法进行比较。
- 评估提示设计(包括示例和引导提示)如何影响查询效果。
- 确定在系统综述中使用 ChatGPT 进行查询制定的 caveats 与局限性。
提出的方法
- 为查询制定设计并评估不同复杂度的提示(简单、详细、含示例)。
- 评估无引导与有引导提示的方法。
- 使用单提示与多提示 refinement 工作流生成并改进查询。
- 在标准集合上测试提示(CLEF TAR 2017/2018 与 Seed Collection),如有种子研究。
- 通过 Entrez API 执行生成的 PubMed 查询并计算 precision, recall, and F-measures。
- 分析多次运行的变异性以评估提示的稳定性和鲁棒性。
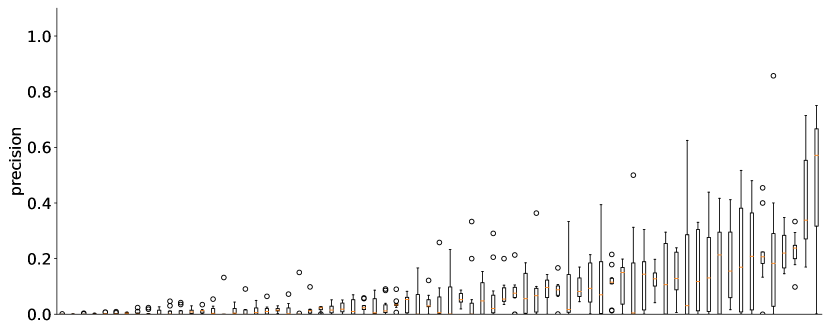
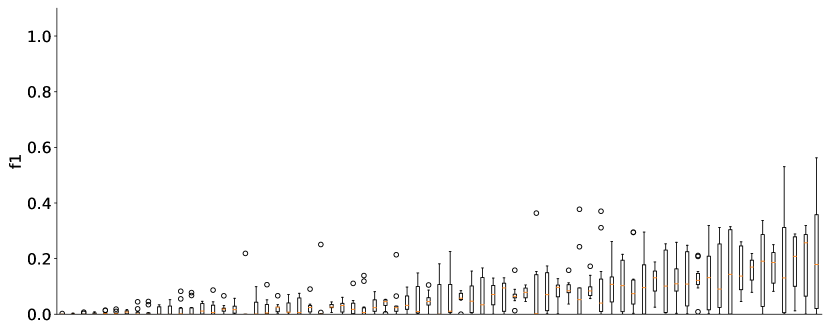
实验结果
研究问题
- RQ1RQ1: ChatGPT 与当前最先进的方法在制定和改进系统综述布尔查询方面的比较如何?
- RQ2RQ2: 用来生成系统综述布尔查询的提示在多大程度上影响 ChatGPT 生成的布尔查询的有效性?
- RQ3RQ3: 通过模仿当前最先进的自动布尔查询生成方法的过程,使用多个提示来引导查询制定,会对 ChatGPT 的作用有何影响?
- RQ4RQ4: 使用 ChatGPT 创建系统综述布尔查询的注意事项与潜在挑战是什么?
主要发现
- ChatGPT 生成的查询通常比基线自动方法具有更高的精准度,但召回率较低。
- 使用包含来自真实系统综述的高质量示例(HQE)的提示,在 F1 和 F3 分数以及召回方面始终优于不包含此类示例的提示。
- 有引导的提示(多步骤提示)在有种子研究时,尤其在制定任务中,可能优于单一提示。
- 使用 ChatGPT 的查询改进提高了精准度和 F1,同时降低召回;建议从高召回率的种子查询开始以在改进后保持覆盖。
- 有效性在不同运行和提示之间变化,显示出波动性;ChatGPT 给出的 MeSH 术语建议尤其薄弱。
- 在提示中提供示例查询通常比仅描述任务对性能更有利。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。