[论文解读] Can multiple-choice questions really be useful in detecting the abilities of LLMs?
该论文分析 MCQ 在评估 LLM 的有效性方面的表现,揭示顺序敏感性和与长形式生成的不一致,并提出在不同 QA 格式中衡量一致性和置信度的方法。
Multiple-choice questions (MCQs) are widely used in the evaluation of large language models (LLMs) due to their simplicity and efficiency. However, there are concerns about whether MCQs can truly measure LLM's capabilities, particularly in knowledge-intensive scenarios where long-form generation (LFG) answers are required. The misalignment between the task and the evaluation method demands a thoughtful analysis of MCQ's efficacy, which we undertake in this paper by evaluating nine LLMs on four question-answering (QA) datasets in two languages: Chinese and English. We identify a significant issue: LLMs exhibit an order sensitivity in bilingual MCQs, favoring answers located at specific positions, i.e., the first position. We further quantify the gap between MCQs and long-form generation questions (LFGQs) by comparing their direct outputs, token logits, and embeddings. Our results reveal a relatively low correlation between answers from MCQs and LFGQs for identical questions. Additionally, we propose two methods to quantify the consistency and confidence of LLMs' output, which can be generalized to other QA evaluation benchmarks. Notably, our analysis challenges the idea that the higher the consistency, the greater the accuracy. We also find MCQs to be less reliable than LFGQs in terms of expected calibration error. Finally, the misalignment between MCQs and LFGQs is not only reflected in the evaluation performance but also in the embedding space. Our code and models can be accessed at https://github.com/Meetyou-AI-Lab/Can-MC-Evaluate-LLMs.
研究动机与目标
- 评估 MCQs 是否能够准确衡量跨语言(中文与英文)和数据集的 LLM 能力。
- 考察 MCQ 选项顺序如何影响 LLM 输出。
- 比较 MCQ 与长形式生成(LFGQ)格式在直接输出、标记 logits、及嵌入向量中的表现。
- 提出量化输出一致性和模型置信度的方法。
- 就何时在 QA 基准中使用 MCQ 与 LFGQ 提供指引。
提出的方法
- 在四个 QA 数据集上评估九个 LLM(中文 CARE-MI、中文 M3KE、英文 ARC、英文 MATH)。
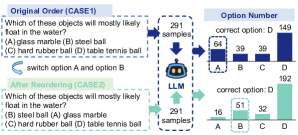
- 通过重新排列 MCQ 选项并应用卡方检验来检测分布偏移,从而测试顺序敏感性。
- 在直接输出、标记 logits、和隐藏嵌入空间中比较 MCQ 与 LFGQ 格式(含统一置信度和 ECE 等分析)。
- 分析格式之间的相关性,以及一致性与准确性之间的关系。
- 使用前提示和后提示以引出简练回答,并实现自动置信度计算。
实验结果
研究问题
- RQ1双语数据集中,MCQ 选项的排列如何影响 LLM 的回答?
- RQ2在直接输出、标记 logits、嵌入空间之间,哪些方法适合比较 MCQ 与 LFGQ?
- RQ3MCQ 与 LFGQ 之间的一致性和不匹配程度如何,格式在校准与一致性方面有何差异?
主要发现
- LLMs 在双语 MCQ 中表现出顺序敏感性,更偏好位于第一位的答案。
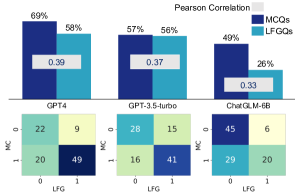
- 对于相同问题,MCQ 与 LFGQ 的答案在不同格式之间相关性较低。
- 更高的一致性并不一定转化为更高的准确性。
- MCQ 的校准效果较差(ECE 更高)于 LFGQ 和 TFQ,而嵌入空间在若干层之间显示格式不一致。
- 在某些层,MCQ 与 LFGQ 的嵌入在某些模型中可分离,但在后期层趋同。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。