[论文解读] ChatPose: Chatting about 3D Human Pose
PoseGPT 是一个多模态 LLM 框架,将 SMPL 姿态作为独特的令牌嵌入,以从文本或图像生成并推理三维人体姿态,引入推测性姿态生成和基于推理的姿态估计基准。
We introduce ChatPose, a framework employing Large Language Models (LLMs) to understand and reason about 3D human poses from images or textual descriptions. Our work is motivated by the human ability to intuitively understand postures from a single image or a brief description, a process that intertwines image interpretation, world knowledge, and an understanding of body language. Traditional human pose estimation and generation methods often operate in isolation, lacking semantic understanding and reasoning abilities. ChatPose addresses these limitations by embedding SMPL poses as distinct signal tokens within a multimodal LLM, enabling the direct generation of 3D body poses from both textual and visual inputs. Leveraging the powerful capabilities of multimodal LLMs, ChatPose unifies classical 3D human pose and generation tasks while offering user interactions. Additionally, ChatPose empowers LLMs to apply their extensive world knowledge in reasoning about human poses, leading to two advanced tasks: speculative pose generation and reasoning about pose estimation. These tasks involve reasoning about humans to generate 3D poses from subtle text queries, possibly accompanied by images. We establish benchmarks for these tasks, moving beyond traditional 3D pose generation and estimation methods. Our results show that ChatPose outperforms existing multimodal LLMs and task-specific methods on these newly proposed tasks. Furthermore, ChatPose's ability to understand and generate 3D human poses based on complex reasoning opens new directions in human pose analysis.
研究动机与目标
- 推动在统一模型中将图像/文本理解 bridged 与三维人体姿态的结合。
- 通过基于聊天的多模态 LLM 实现 SMPL 姿态的生成与估计。
- 引入推测性姿态生成和基于推理的姿态估计作为新任务。
提出的方法
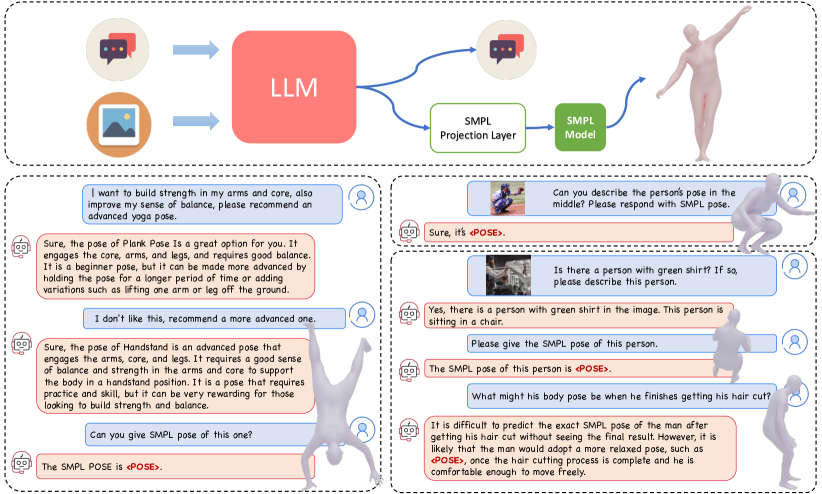
- 在多模态大模型中将 SMPL 姿态嵌入为一个 <POSE> 令牌,通过 MLP 投影层将语言嵌入映射到 SMPL 姿态参数。
- 在训练过程中保持视觉编码器冻结;在训练仅 SMPL 投影层的同时,使用 LoRA 对 LLM 进行微调。
- 在文本到姿态、图像到姿态以及多模态指令跟随数据上进行训练,以实现姿态生成和姿态推理。
实验结果
研究问题
- RQ1一个多模态 LLM 是否能够从文本或图像理解并生成三维人体姿态(SMPL)?
- RQ2模型是否能够利用世界与场景知识进行推测性姿态生成和基于推理的姿态估计?
- RQ3在姿态生成和姿态估计(包括基于推理的任务)方面,PoseGPT 与任务特定及其他多模态基线相比有何差异?
主要发现
| Method | MPJPE 3DPW (mm) | PA-MPJPE 3DPW (mm) | MPJRE 3DPW | MPJPE H36M (mm) | PA-MPJPE H36M (mm) | MPJRE H36M |
|---|---|---|---|---|---|---|
| PoseGPT (ours) | 163.6 | 81.9 | 10.4 | 126.0 | 82.4 | 10.4 |
- PoseGPT 可以从文本或图像生成 SMPL 姿态,并实现对话驱动的姿态推理。
- 在推测性姿态生成方面,PoseGPT 胜过 PoseScript,并在与传统姿态生成基线的比较中取得了竞争性结果。
- 在基于推理的姿态估计方面,PoseGPT 超越了其他多模态大模型和任务特定方法,尽管在标准姿态估计指标上,传统姿态估计器仍更强。
- 该模型对遮挡具有鲁棒性,并受益于使用姿态嵌入而非文本姿态描述。
- 使用更大的 LLM 主干(13B 相较于 7B)提升了 PoseGPT 的性能。
- 该方法开放了两个新基准(SPG 与 RPE),用于评估三维姿态情境中的推理能力。
![Figure 2 : Method and Training Overview. Our model is composed of a multi-modal LLM (with vision encoder, vision projection layer and LLM), a SMPL projection layer, and the parametric human body model, i.e. SMPL [ 29 ] . The multi-modal LLM processes text and image inputs (if provided) to generate t](https://ar5iv.labs.arxiv.org/html/2311.18836/assets/x2.png)
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。