[论文解读] ChatSpamDetector: Leveraging Large Language Models for Effective Phishing Email Detection
ChatSpamDetector 使用大语言模型通过将邮件转换为对LLM友好的提示来检测钓鱼邮件,并为其决策提供详细的推理,使用 GPT-4 在多样化的钓鱼邮件数据集上达到 99.70% 的准确率。
The proliferation of phishing sites and emails poses significant challenges to existing cybersecurity efforts. Despite advances in malicious email filters and email security protocols, problems with oversight and false positives persist. Users often struggle to understand why emails are flagged as potentially fraudulent, risking the possibility of missing important communications or mistakenly trusting deceptive phishing emails. This study introduces ChatSpamDetector, a system that uses large language models (LLMs) to detect phishing emails. By converting email data into a prompt suitable for LLM analysis, the system provides a highly accurate determination of whether an email is phishing or not. Importantly, it offers detailed reasoning for its phishing determinations, assisting users in making informed decisions about how to handle suspicious emails. We conducted an evaluation using a comprehensive phishing email dataset and compared our system to several LLMs and baseline systems. We confirmed that our system using GPT-4 has superior detection capabilities with an accuracy of 99.70%. Advanced contextual interpretation by LLMs enables the identification of various phishing tactics and impersonations, making them a potentially powerful tool in the fight against email-based phishing threats.
研究动机与目标
- 推动在传统过滤器对分类缺乏解释时对抗钓鱼邮件的防御。
- 提出一个将电子邮件转换为供LLM分析的提示以检测钓鱼邮件的系统。
- 提供详细的、富含推理的报告,帮助用户决定如何处理可疑邮件。
提出的方法
- 解析和解码 .eml 邮件以提取头部和正文,同时省略服务器过滤头。
- 通过 HTML/文本修剪,将长邮件简化以适应 LLM 的令牌限制(3,000 个令牌)。
- 生成任务特定的提示,并使用连锁思维提示进行结构化分析。
- 使用函数调用让LLMs返回包含 is_phishing、phishing_score、brand_impersonated、rationales 和 brief_reason 的JSON报告。
- 在一个钓鱼/正常邮件数据集上对比基线,评估多个LLM(GPT-4、GPT-3.5、Llama2、Gemini Pro)的表现。
- 比较提示策略(Normal 与 Simple 提示),并分析误报/漏报。
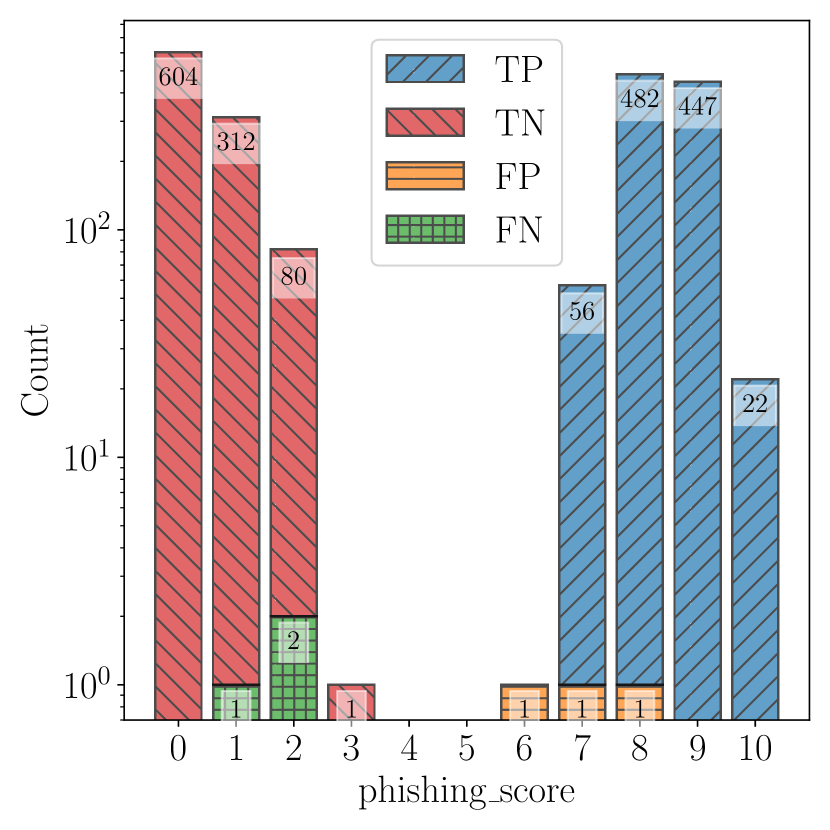
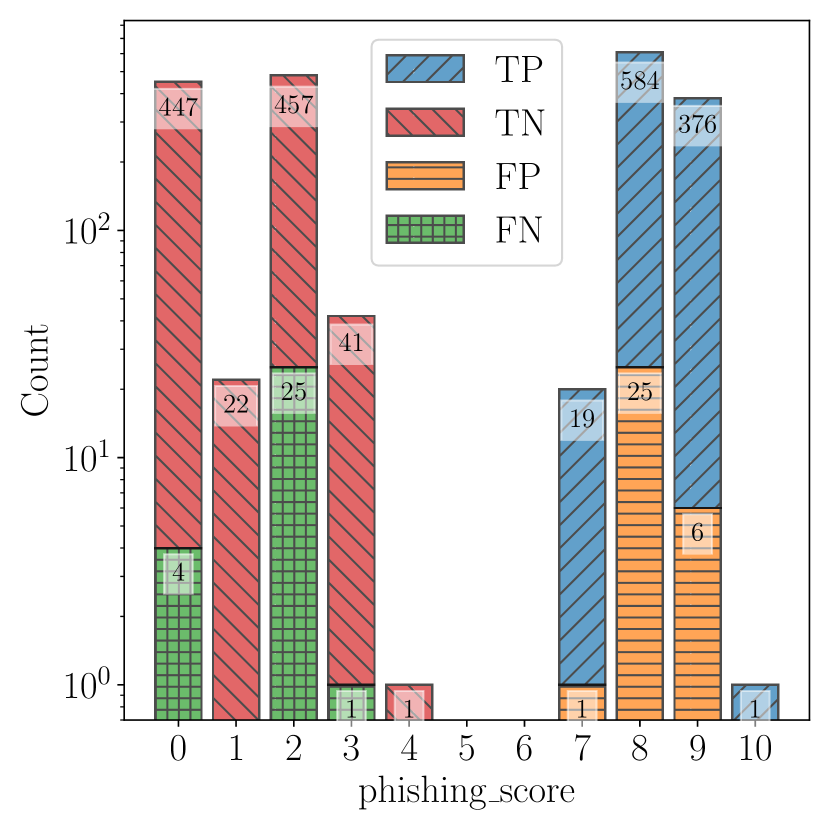
实验结果
研究问题
- RQ1在基于邮箱派生提示下,LLMs 能否可靠地检测钓鱼邮件?
- RQ2在当前数据集上,不同的LLM(GPT-4、GPT-3.5、Llama2、Gemini Pro)在钓鱼检测性能方面有何差异?
- RQ3提供结构化推理与品牌冒充信息是否提升用户的信任度和决策?
- RQ4提示设计(normal 与 simple)对精确度、召回率和误报有何影响?
- RQ5系统输出与现代钓鱼邮件上的传统基线分类器相比如何?
主要发现
| 系统 | 模型 | 提示 | 真阳性 | 假阳性 | 真阴性 | 假阴性 | 精确度 | 召回率 | 准确率 |
|---|---|---|---|---|---|---|---|---|---|
| ChatSpamDetector | GPT-4 | Normal | 1,007 | 3 | 997 | 3 | 99.70% | 99.70% | 99.70% |
| ChatSpamDetector | GPT-4 | Simple | 1,001 | 4 | 996 | 9 | 99.60% | 99.11% | 99.35% |
| ChatSpamDetector | GPT-3.5 | Normal | 980 | 32 | 968 | 30 | 96.84% | 97.03% | 96.92% |
| ChatSpamDetector | GPT-3.5 | Simple | 697 | 6 | 994 | 313 | 99.15% | 69.01% | 84.13% |
| ChatSpamDetector | Llama2 | Normal | 950 | 361 | 639 | 60 | 72.46% | 94.06% | 79.05% |
| ChatSpamDetector | Llama2 | Simple | 790 | 9 | 991 | 220 | 98.87% | 78.22% | 88.61% |
| ChatSpamDetector | Gemini Pro | Normal | 991 | 21 | 979 | 19 | 97.92% | 98.12% | 98.01% |
| ChatSpamDetector | Gemini Pro | Simple | 977 | 6 | 994 | 33 | 99.39% | 96.73% | 98.06% |
| Baseline A | - | - | 580 | 374 | 626 | 430 | 60.80% | 57.43% | 60.00% |
| Baseline B | - | - | 564 | 413 | 587 | 446 | 57.73% | 55.84% | 57.26% |
| Baseline C | - | - | 923 | 827 | 173 | 87 | 52.74% | 91.39% | 54.53% |
| Baseline D | - | - | 941 | 208 | 792 | 69 | 81.90% | 93.17% | 86.22% |
- 使用普通提示的 GPT-4 达到 99.70% 的准确率,优于其他模型和基线。
- 简单提示降低了若干模型的误报,但降低了召回率;普通提示整体上提升了钓鱼识别并减少了误报。
- GPT-4 通常在评估的模型中提供最强的性能(准确率、精确率、召回率)(GPT-4 > GPT-3.5 > Gemini Pro > Llama2)。
- 该系统在提取并报告头部和正文中的关键指标(包括品牌冒充和社会工程技巧)方面实现了高水平的钓鱼检测。
- 与基线相比,ChatSpamDetector 在同一数据集上显著优于传统基于特征的方法。
- 报告的延迟和成本因模型而异,GPT-4 平均每次请求约 12.5 秒,GPT-3.5 约 2.5 秒,且 GPT-4 成本更高。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。