[论文解读] ClinicalGPT: Large Language Models Finetuned with Diverse Medical Data and Comprehensive Evaluation
ClinicalGPT 是一个针对医疗领域的大语言模型,使用多样化的真实世界医疗数据进行微调,并在医疗对话、考试、诊断和问答任务中进行评估,优于若干基线模型。
Large language models have exhibited exceptional performance on various Natural Language Processing (NLP) tasks, leveraging techniques such as the pre-training, and instruction fine-tuning. Despite these advances, their effectiveness in medical applications is limited, due to challenges such as factual inaccuracies, reasoning abilities, and lack grounding in real-world experience. In this study, we present ClinicalGPT, a language model explicitly designed and optimized for clinical scenarios. By incorporating extensive and diverse real-world data, such as medical records, domain-specific knowledge, and multi-round dialogue consultations in the training process, ClinicalGPT is better prepared to handle multiple clinical task. Furthermore, we introduce a comprehensive evaluation framework that includes medical knowledge question-answering, medical exams, patient consultations, and diagnostic analysis of medical records. Our results demonstrate that ClinicalGPT significantly outperforms other models in these tasks, highlighting the effectiveness of our approach in adapting large language models to the critical domain of healthcare.
研究动机与目标
- 动机:由于通用模型在事实准确性与锚定方面的挑战,强调需要医学专业领域的LLM。
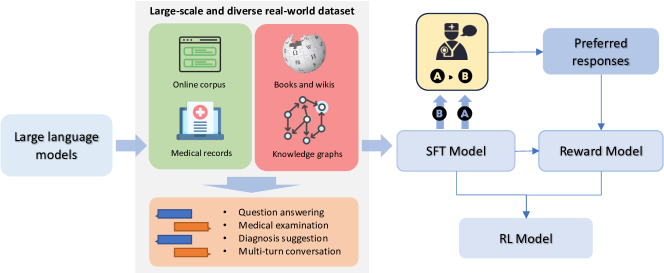
- 汇集大规模的真实世界医疗数据(病历、知识图谱知识、考试、对话)以进行定向微调。
- 建立覆盖对话、考试、诊断和问答任务的综合评估框架。
- 展示参数高效微调(LoRA)和基于RLHF的优化,以提升临床表现。
提出的方法
- 使用领域数据和知识图谱派生的问答对,通过有监督的指令微调对 BLOOM-7B 进行微调。
- 从人工排序输出构建奖励模型,以引导强化学习。
- 使用近端策略优化(PPO)进行强化学习,使输出在医学准确性和有用性上对齐,同时对大幅度策略变更进行惩罚(KL惩罚)。
- 使用 LoRA 进行参数高效自适应和 Zero-2 内存优化,以实现可扩展的训练。
- 整合多样化的医疗数据集(cMedQA2、cMedQA-KG、MD-EHR、MEDQA-MCMLE、MedDialog),并将病历转换为文本生成任务。
实验结果
研究问题
- RQ1相比开放模型,ClinicalGPT 在医疗对话任务中的表现如何?
- RQ2领域特定数据与奖励引导微调能否提升医学知识问答、考试准确性和诊断推理?
- RQ3参数高效微调与 RLHF 对临床可靠性和安全性的影响是什么?
主要发现
- 在医疗对话方面,CLinicalGPT 在 BLEU-1 上达到 13.9,BLEU-2 3.7,BLEU-3 2.0,BLEU-4 1.2,GLEU 0.9,ROUGE-1 27.9,ROUGE-2 6.5,ROUGE-L 21.3。
- 在医学检查(诊断任务)在各疾病组的表现中,ClinicalGPT 在所报告表格中的平均准确率为 37.6%,在各疾病组的总体平均为 80.9%,超越了表6中的 ChatGLM-6B、LLAMA-7B、BLOOM-7B 等模型。
- 在针对 BLOOM-7B、LLAMA-7B 和 ChatGLM-6B 的医学QA评估中,ClinicalGPT 分别在对比中获胜比例为 89.7%、85.0% 和 67.2%(相对于 BLOOM-7B、LLAMA-7B 和 ChatGLM-6B 的胜出)。
- 诊断中按疾病组的平均表现在消化系统(90.1%)和泌尿系统(89.9%)最强,风湿免疫组在各类别中最高为 47.4%。
- 该框架和结果表明,在使用领域数据微调LLMs并对医疗任务采用带 PPO 的 RLHF 时可获得显著提升。
- ClinicalGPT 在多个评估维度上优于基线模型,凸显多样化医疗数据和有针对性评估的价值。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。